从SmallCap出发切入Image Caption
2025年3月8日,星期六,晴天☀️,第53篇博客。今天是3·8妇女节,恭祝所有女神节日快乐!!
SmallCap: Lightweight Image Captioning Prompted with Retrieval Augmentation
研究背景
- 研究问题: 这篇文章要解决的问题是如何在减少计算资源消耗的情况下,生成高质量的Image Caption。当前的图像描述模型通常需要大规模的数据和模型,导致预训练和微调的成本很高。
- 研究难点: 该问题的研究难点包括:1)如何在减少模型参数的同时保持模型的性能;2)如何在不进行微调的情况下,使模型能够适应新的领域;3)如何有效地利用大规模的外部数据进行训练。
- 相关工作: 相关工作包括基于大规模数据训练的图像描述模型,如LEMONHuge、SimVLMHuge和BLIPCapFilt-L等。此外,还有一些工作尝试通过冻结部分模型参数来减少训练成本,如ClipCap和I-Tuning。检索增强生成(Retrieval-Augmented Generation)是另一个相关的研究方向,但在图像描述任务中尚未得到充分探索。
研究方法
这篇论文提出了SMALLCAP模型,用于解决图像描述任务中的计算资源消耗问题。具体来说,SMALLCAP通过检索增强和轻量化设计来实现高效的图像描述生成。
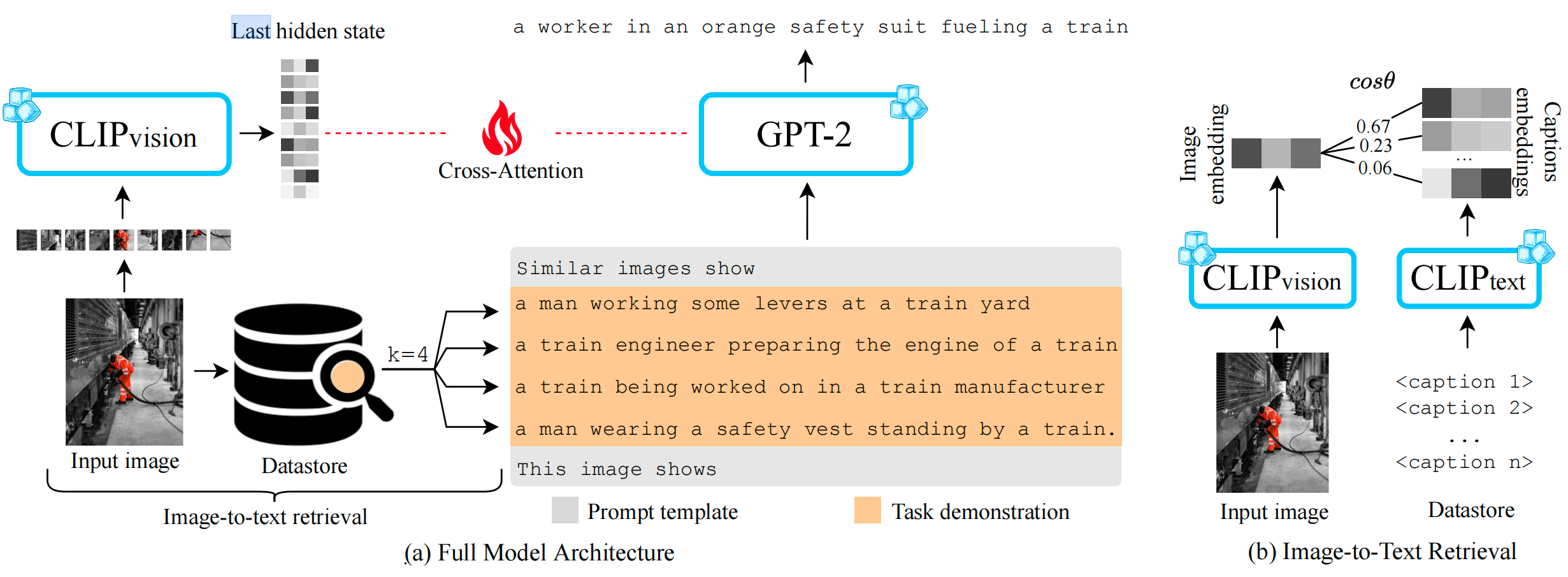
模型架构: SMALLCAP结合了预训练的CLIP视觉编码器和GPT-2语言解码器。CLIP编码器用于处理输入图像,生成一系列图像块嵌入。GPT-2解码器用于生成描述文本。为了减少训练参数,SMALLCAP仅在CLIP编码器和GPT-2解码器之间引入了新的跨注意力层,这些层的参数是可以训练的。
检索增强: SMALLCAP通过在训练和推理过程中使用检索到的相关描述来增强生成能力。具体来说,对于输入图像,模型会从数据存储库中检索k个相关的描述,并将这些描述作为提示输入到解码器中。解码器根据图像特征和检索到的描述生成最终的图像描述。
轻量化设计: 为了进一步减少训练参数,SMALLCAP通过调整跨注意力层的投影矩阵维度来控制可训练参数的数量。默认情况下,投影矩阵的维度设置为64,但可以根据需要进行调整。
实验设计
- 数据收集: 实验使用了COCO数据集进行训练和评估。此外,还在nocaps数据集上进行了跨领域评估。
- 实验设置: SMALLCAP的编码器和解码器分别初始化自CLIP-ViT-B/32和GPT-2Base。模型仅训练跨注意力层的参数,其他参数保持冻结。训练使用AdamW优化器,初始学习率为1e-4,批量大小为64,训练10个epoch。
- 检索机制: 在训练过程中,模型使用CLIP-ResNet-50x64编码器对输入图像和数据存储库中的描述进行编码,并通过余弦相似度进行最近邻搜索,检索k个相关描述。推理过程中,模型使用beam search解码生成描述。
结果与分析
- COCO数据集结果: 在COCO数据集上的实验结果表明,SMALLCAP在仅有7M可训练参数的情况下,性能与其他轻量级模型相当,甚至在某些指标上超过了更大的模型。
- nocaps数据集结果: 在nocaps数据集上的跨领域评估中,SMALLCAP表现出色,显著优于其他轻量级模型,并且在某些情况下接近甚至超过了经过微调的大规模模型。
- 检索增强的影响: 实验结果表明,检索增强对SMALLCAP的性能有显著提升。通过检索相关描述,模型能够更好地适应不同的领域和任务。
总体结论
这篇论文提出了SMALLCAP模型,通过检索增强和轻量化设计,实现了高效的图像描述生成。实验结果表明,SMALLCAP在减少计算资源消耗的同时,保持了较高的性能,并且能够在不同领域之间进行有效的迁移。未来的研究可以进一步探索检索增强在其他多模态任务中的应用,并扩展检索数据的使用规模。
论纲梳理
五步法:
- 分析标题
- 目录概览
- 先读结论
- 再读导论
- 重点章节阅读
实用技巧:将所有读过的内容用自己的话复述出来,最后是写下来!
标题分析
SmallCap: Lightweight Image Captioning Prompted with Retrieval Augmentation
主标题:SmallCap
副标题:Lightweight Image Captioning Prompted with Retrieval Augmentation
作者起这样一个标题意味着什么呢?Cap大概率要和Image Caption有关,加上Small形容词是想说明更小巧的模型吗?再看副标题,Lightweight Image Captioning意味着要进行轻量化;Lightweight Image Captioning Prompted with Retrieval Augmentation-利用检索增强功能提示轻量级图像标题。也就是说作者想通过使用检索增强技术来轻量化Image Caption的过程。
根据题目展开的可能联想:
思考1:为什么要轻量化?轻量化是不是由于之前的研究造成了计算资源消耗大、计算成本大、数据规模大造成的?(当然这是通过阅读Abstract了解到的)
思考2:计算资源消耗在哪里了?检索增强技术是如何减少计算资源消耗的?
思考2:探究如何在减少计算资源消耗的情况下,生成高质量的Image Caption。
先读Conclusion,自己复述
In this paper, we propose SMALLCAP, an image captioning model augmented with retrieval, which is light to train and can be transferred across domains without retraining. Results on the COCO dataset show that SMALLCAP is competitive to other lightweight-training models despite having substantially less trainable parameters, instead leveraging non-parametric information from a datastore of text. Out-of-domain evaluations show that SMALLCAP can also perform training-free domain transfer when given access to a datastore with target-domain data. Our model further benefits from diverse web and human-labeled data in addition to or in place of target-domain data. We find that SMALLCAP benefits not just from access to image captions, but also to video and audio captions (resources neglected in image captioning work in the past).
本文提出了一种新型轻量级Image Caption模型-SmallCap,训练方式简单且方便跨领域使用。由于利用了文本数据存储的非参数信息,使得可训练参数大大减少,但是并没有影响SmallCap在COCO数据集上的良好表现。如果可以接入包含目标域的数据库,SmallCap可以实现免训练跨领域转换。Web数据和人类标签数据会使SmallCap更加多元化。SmallCap模型还可以从video and audio captions中获益。
SMALLCAP’s small size and impressive performance in out-of-domain settings attest to the potential of retrieval augmentation as an alternative to the expensive training found in large pre-trained vision-and-language models and the costly finetuning that even previous lightweight-training models require in order to adapt to different image captioning datasets. Future work can apply our retrieval augmentation approach to a wider range of multimodal tasks, and further explore the scalability of the data used for retrieval.
SmallCap小巧的体积和良好的表现证明了检索增强技术可以代替昂贵的VLM预训练和先前轻量级训练模型的高开销微调过程。未来可以将检索增强的方法用到更广泛的多模态任务中去,探索用于检索数据的可扩展性。
一句话总结:本文提出了一种轻量级Image Caption模型——SmallCap,相比于使用高成本的VLM预训练和高开销的lightweight-training模型微调(相比于预训练和微调的成本持续增加),SmallCap结合检索增强技术大大降低了训练成本并在COCO数据集上取得良好的表现。
再读导论
先进的Image Caption是通过在大规模数据集上的大模型训练完成的。规模的扩大导致了更高计算量的预训练和微调成本。不同模型版本所需的视觉域和终端用户的实际应用也不同。
ClipCap 和 I-Tuning模型都对降低成本做出了努力,它们主要是使用了现成的预训练视觉编码、解码器。模型参数被预先冻结,只训练两者之间的映射来完成Image Caption任务。参数规模确实减少了、速度也有所提高了。虽然模型易于管理起来,但是仍然不适合前文提到的实际应用,因为模型对于每个用例都需要单独训练。
SmallCap使得lightweight training, training-free domain transfer,and exploitation of large data in a training-free fashion(轻量级训练,无需训练的域转移,以及以无需训练的方式利用大数据)成为可能。
结合检索增强提示的SmallCap克服了一个关键限制:需要明确的微调以使用到新的领域,这种方式证明了在多模态任务中的潜力。
导论首先介绍了当前Image Caption领域发展的主要趋势:数据规模变大,计算成本持续增加。而先前的模型如ClipCap 和 I-Tuning确实对降本有明显的提高,但是增效方面并没有取得良好的性能,并不能领过适配多种落地任务,也就是说可以降本但无法增效。而SmallCap的提出克服了需要多次明确微调以应用到新领域的限制,实现了降本增效的效果。
最后读重要章节
model
编码器:CLIP-ViT-B/32,解码器:$GPT-2_{Base}$
难点理解 - multi-head cross-attention layer:
编码器与解码器模型的运算在两个向量空间维度,所以要通过multi-head cross-attention layer将它们连接起来,使得解码器的每一层都关注编码器的输出。
Small降本增效的方法:
- 通过冻结编码-解码器,只训练他们之间的随机初始化交叉住意层来降低计算开销并提高泛化。
- 通过交叉注意力层的的投影矩阵维度(d)控制可训练参数的数量。
Prompting with Retrieved Captions
相比于先前的image2image检索方法,本文创新地运用了image2text方法。将数据集中的image captions作为外挂知识库。检索阶段使用完整的CLIP模型与视觉-文本编码器,将两种模态数据映射到共享的向量空间。
编码器会编码input image和数据存储的内容,通过cos相似度检索得到与input image最相似的k个文本项。
解码器会将检索阶段使用的prompt作为输入Tokens,然后依照特征图像和task demonstration生成captioin。
实验复现
论文源代码地址:https://github.com/RitaRamo/smallcap
环境配置
代码环境基于python3.9
1 | |
模型训练
数据
https://www.kaggle.com/datasets/shtvkumar/karpathy-splits
从上面的链接中下载COCO Karpathy splits的dataset_coco.json文件并放置在data/目录下
https://cocodataset.org/#download
从上面的链接中下载2017版本的COCO images(train、val、test),并将文件放置在data/images/下
http://images.cocodataset.org/zips/train2017.zip
http://images.cocodataset.org/zips/val2017.zip
http://images.cocodataset.org/zips/test2017.zip
处理
目前基于ResNet的CLIP模型仍然无法从Hugging Face下载,所以需要通过pip安装
1 | |
提取特征:
1 | |
检索captions:
1 | |
模型训练
完成前期所有准备后进行模型训练:
1 | |
Training takes up to 8 hours on a single NVIDIA A100 GPU, using 16 GB of the available memory.
训练完成后,模型以名称<rag/norag> _m保存/例如 RAG_7M,用于训练以检索增强和7m可训练参数训练的型号。
推理
使用训练好的模型进行推理:
1 | |
如果还指定了 --checkpoint_path 则推理将仅使用该检查点运行。否则,将使用 –model_path 中的所有检查点。
如果指定-infer_test推理使用测试数据,则使用否则VAL数据。
1 | |
在每个相应的checkpoint subdirectory中,将模型预测存储为<val/test> _preds.json。