DeepSeek YYDS
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
![]()
与普通LLM相比,推理LLM倾向于在回答之前讲问题分解为更小的步骤(推理步骤和思维链),这类模型是在让模型学习如如何回答。
Intro
文章介绍了DeepSeek-AI团队开发的第一代推理模型DeepSeek-R1-Zero和DeepSeek-R1。DeepSeek-R1是一种基于大规模强化学习训练的模型,无需监督微调作为初步步骤,展现出强大的推理能力。
优势:推理能力强
挑战:可读性差、语言混合
模型提出的标志性意义:DeepSeek-R1迈出了使用纯强化学习 (RL) 提高语言模型推理能力的第一步,目标是探索 LLM 在没有任何监督数据的情况下开发推理能力的潜力,重点关注LLM通过纯 RL 过程进行模型自身进化。
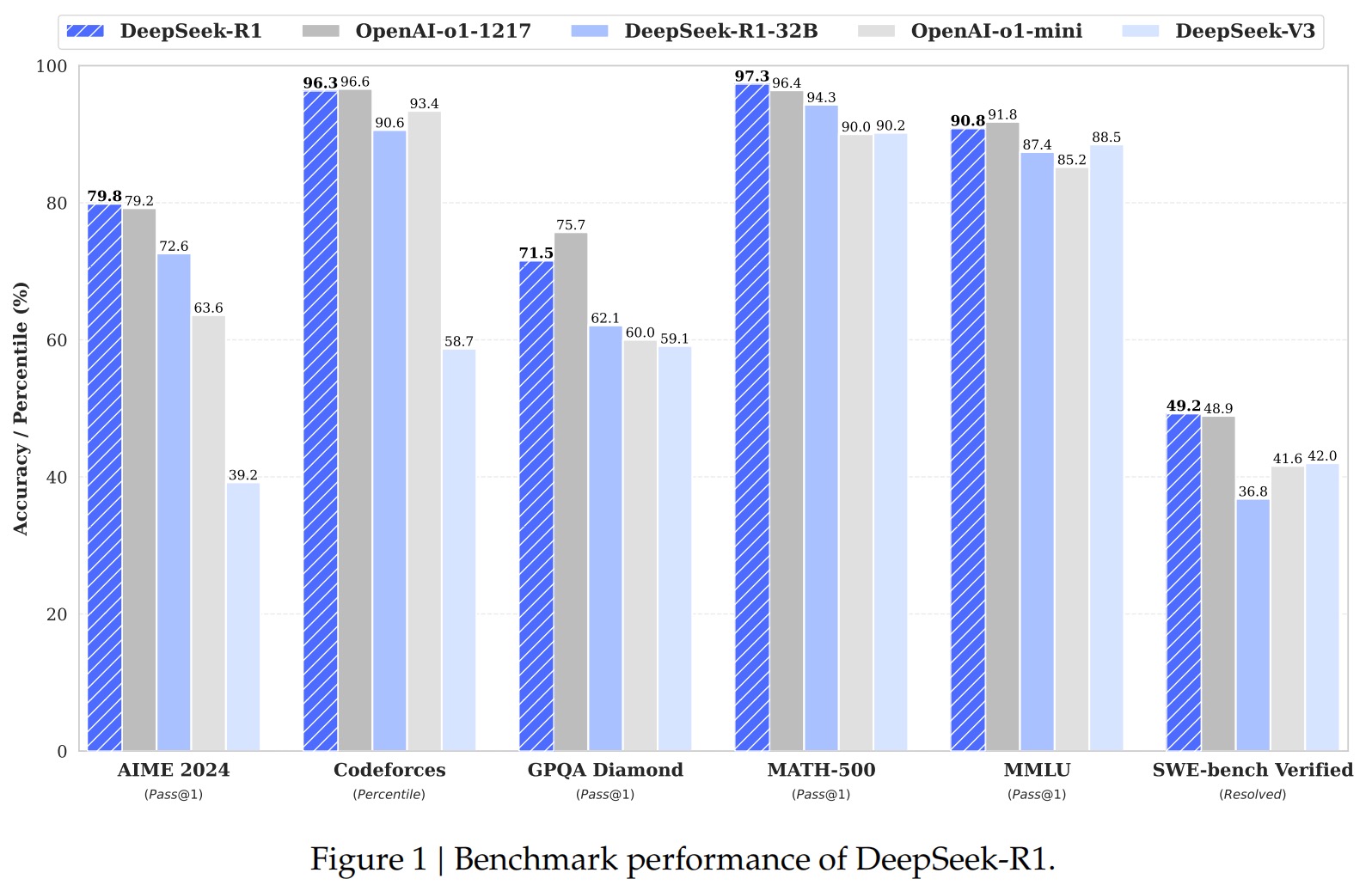
自身进化的同时提高了推理性能,同时,因为无需任何监督数据,极大地降低了成本。LLM拼多多称号当之无愧!国产骄傲!
DeepSeek-R1-Zero represents a pure RL approach without relying on cold-start data, achieving strong performance across various tasks.
DeepSeek-R1 is more powerful, leveraging cold-start data alongside iterative RL fine-tuning.
DeepSeek-R1-Zero 是使用 DeepSeek-V3-Base 作为基础模型,结合GRPO作为RL框架经过数千步推理训练得到。然而DeepSeek-R1-Zero 遇到了可读性差、语言混合的困难,为了进一步提高推理性能,DeepSeek-AI团队由DeepSeek-R1-Zero模型改进到DeepSeek-R1模型,其结合了少量 cold-start data 和a multi-stage training pipeline。
在RL接近收敛的时候,通过对 RL 检查点进行rejection sampling来创建新的 SFT 数据,并结合 DeepSeek-V3 在写作、事实问答和自我认知等领域的监督数据,然后重新训练 DeepSeek-V3-Base 模型。
Contributions
- Post - training: 在现有基础模型上进行大规模强化学习,该团队直接将RL应用于基础模型,而不依赖于监督微调(SFT)作为一个初步步骤。这种方法允许模型探索思想链(CoT)来解决复杂的问题,从而开发出DeepSeek-R1-Zero。团队也介绍了开发DeepSeek-R1的pipeline。该管道包含了两个RL阶段,以及两个SFT阶段,作为模型的推理和非推理能力的种子。
- Distillation: 蒸馏后使得小模型也具有大能量,该团队证明了更大模型的推理模式可以被提炼为更小的模型,与通过RL在小模型上发现的推理模式相比,从而获得更好的性能。
Future Work
- General Capability: 目前,DeepSeek-R1在function calling, multi-turn, complex role-playing, and JSON output等任务上还不如DeepSeek-V3。接下来,我们计划探索可以利用多长时间的CoT来增强这些领域的任务。
- Language Mixing: DeepSeek-R1目前针对中文和英语进行了优化,这可能导致在处理其他语言的查询时出现语言混合问题。例如,DeepSeek-R1可能会使用英语进行推理和响应,即使查询使用的是英语或中文以外的语言。我们的目标是在未来的更新中解决这一限制。
- Prompting Engineering: 在评估DeepSeek-R1时,我们观察到它对提示很敏感。Few-shot的激励不断地降低了它的表现。因此,我们建议用户直接描述问题,并使用zero-shot指定输出格式,以获得最佳结果。
- Software Engineering Tasks: 由于评估时间长,影响了RL过程的效率,因此大规模的RL在软件工程任务中尚未得到广泛的应用。因此,DeepSeek-R1在软件工程基准测试上并没有显示出比DeepSeek-V3相比的巨大改进。未来的版本将通过对软件工程数据实施拒绝抽样或在RL过程中合并异步评估来提高效率来解决这个问题。
deepseek多模态LLM - Janus-Pro
Unified Multimodal Understanding and Generation with Data and Model Scaling: 通过数据和模型扩展实现统一的多模态理解和生成。
论文解决的当前研究过程中的痛点是:使用相同的视觉编码器处理不同的任务会影响多模态理解的性能。Janus有成果,但是因为训练数据和模型容量有限存在不足。
Janus - Pro的创新在于改进了上述问题,提升了模型的性能,特别是在多模态理解和文本到图像的生成中表现出色。

Janus - Pro作出的改进:
优化训练策略:调整各个阶段的数据比例
扩展训练数据:涵盖多模态理解和生成领域
更大的模型扩展:扩展模型至7B
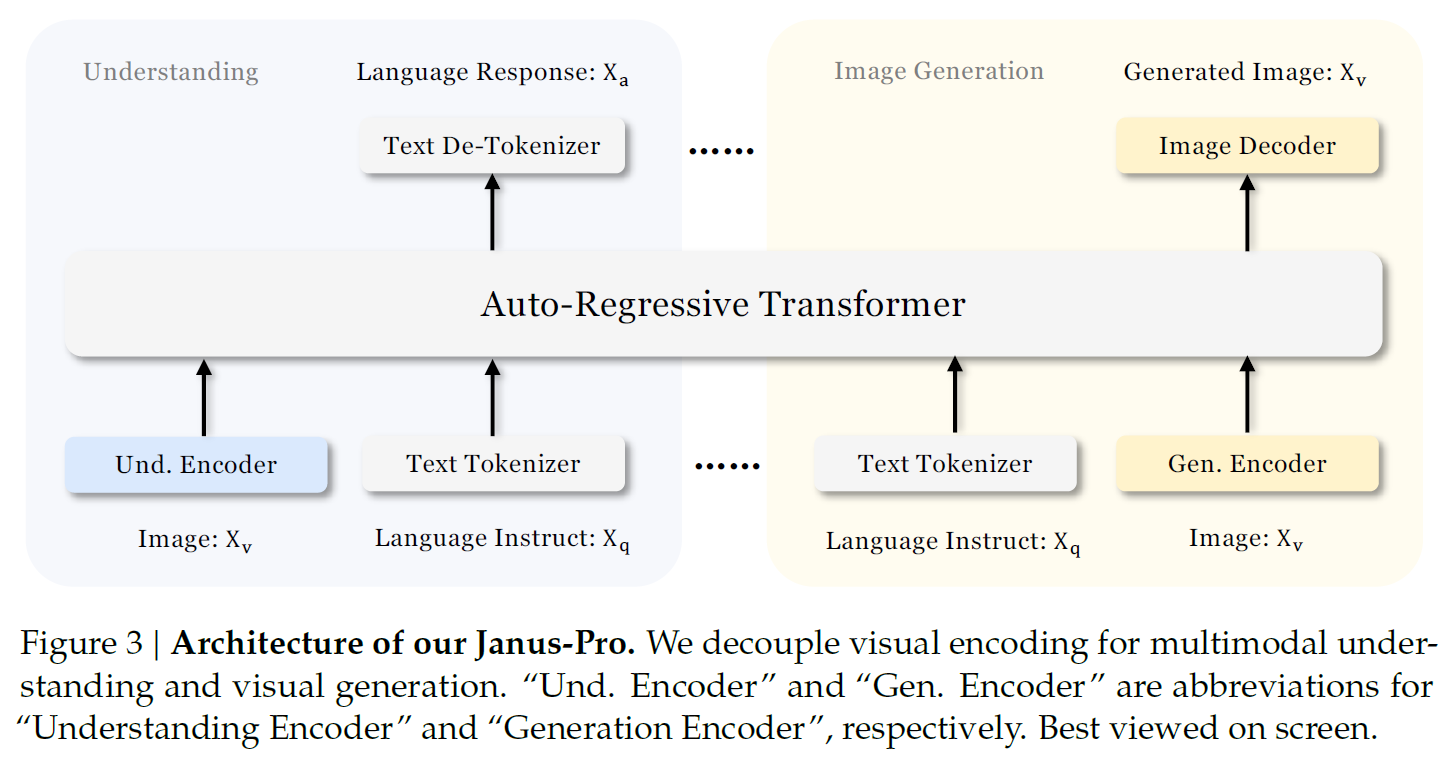
增强了文本到图像的稳定性
DeepSeek的习得过程
复现R1之前务必要把deepseek-v3搞懂!
DeepSeek是站在巨人的肩膀上,摸着OpenAI过河,不要去过分diss OpenAI。deepseek - R1是去“猜”o1的实现过程。DeepSeek是强在推理阶段,在SFT阶段未必是最优的解决方案。
目前市面上大部分指导集成基本上都是部署的蒸馏版的R1,本质上base还是Qwen。
对DeepSeek的认知误区
误区:DeepSeek是全新物种,think是万能钥匙
R1本质上还是一个大模型,只不过是目前推理模型开源最强
误区:DeepSeek-R1不需要提示词
只要是大模型,就一定需要提示词,官方已经提供了34种提示词。之前大模型解决不了的场景,DeepSeek-R1依旧不好解决。
误区:DeepSeek强化学习模型已经是最强模型,干死了OpenAI
DeepSeek的多模态能力不具备、处理一些极端长上下文表现不佳、较03模型基准还有不小差距、base模型好造就了推理能力好(SFT负责记忆,RL负责泛化)
DeepSeek的场景机会
与RAG?与Agent(规划不靠谱)结合?
think是显示过程可以作为微调数据使用,蒸馏得到的qwen学到了一定的推理和数值计算能力
只会做纯量替换,使用其推理能力,目前并不会带来巨大个信。
Ollama本地部署deepseek - R1
硬件配置
电脑 - MacBook Pro
芯片 - Apple M3 Pro
运行内存 - 18GB
安装Ollama
1 | |
通过curl直接安装即可
ollama常用指令
1 | |
下载deepseek-R1模型
1 | |