攻坚克难,务必拿下Transformer,彻底搞懂原理
参考教程:
[1] 动手学深度学习
[2] Data Whale训练营-手撕Transformer
论文的第一作者最喜欢的电影是《变形金刚》
论文的创新点:提出了一个新的简单的网络结构——Transformer,完全依赖于注意力机制而省去了卷积和循环
注意力 就我个人而言,注意力对于我的作用就是提高效率,特别是提高做事情的效率。注意力提升了,在学习的时候就非常认真、专注,从而学习新的东西就会非常快。我发现一旦开始“使用”注意力,就能够快速对与外界刺激作出相应的反馈,无论是背诵、记忆、识别、计算,以上种种行为,在我注意力buff加持下都会比平时懒懒散散的状态下作出的反应要高效。
类比到机器身上,目前借鉴人类的行为模式,机器利用神经网络所从事的两大类主要任务是:运用视觉思维 的识别与分类、运用语言思维 的序列理解。对于这两种思维模式,在注意力buff加持下,执行任务的效率会显著提高。
而设计Transformer架构的主要任务,换言之,设计Transformer架构要解决的核心问题就是利用神经网络去提高机器翻译的准确率,设计的初衷是去解决机器翻译 任务。
注意力有自主性和非自主性之分:非自主性 提示是基于环境中物体的突出性和易见性(比如走在大街上在茫茫人海中一眼就发现了一个漂亮小姐姐…)、自主性 是受到了认知和意识的控制。
机器翻译是序列转换模型 的一个核心问题, 其输入和输出都是长度可变的序列。
论文的摘要中提到了,当下主要的序列转换模型是基于包含一个编码器和一个解码器的复杂卷积神经网络和循环网络。表现最好的模型是使用注意力机制链接编码-解码架构。
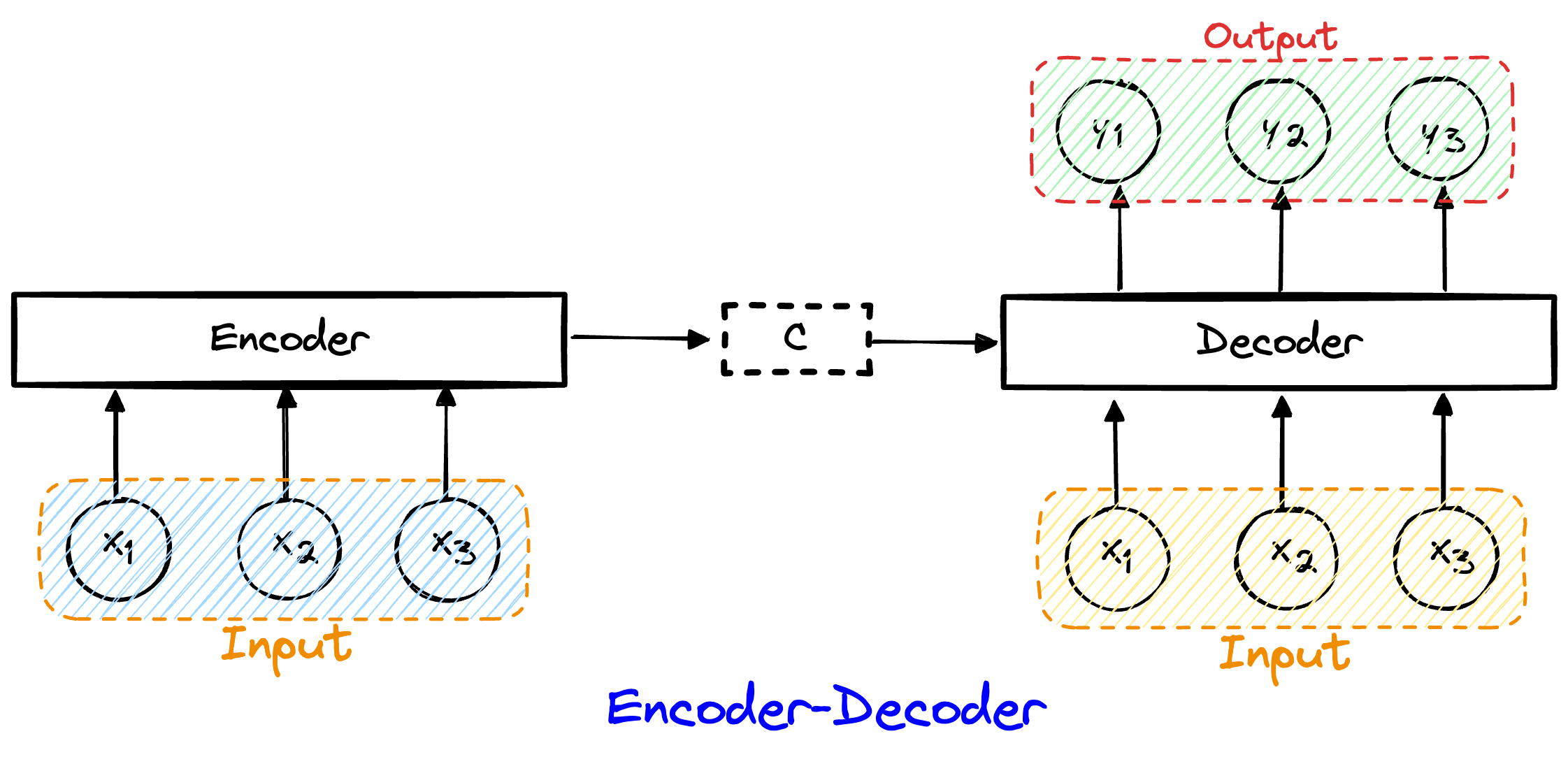
这就不得不学习一下编码-解码架构:
编码器作用:接受一个长度可变的序列作为输入,将其转换为固定形式 的编码状态。
解码器作用:将固定形式的编码状态映射 到长度可变的变长序列。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 class Encoder (nn.Module):"""编码器-解码器架构的基本编码器接口""" def __init__ (self, **kwargs ):super (Encoder, self ).__init__(**kwargs)def forward (self, X, *args ):raise NotImplementedErrorclass Decoder (nn.Module):"""编码器-解码器架构的基本解码器接口""" def __init__ (self, **kwargs ):super (Decoder, self ).__init__(**kwargs)def init_state (self, enc_outputs, *args ):raise NotImplementedErrordef forward (self, X, state ):raise NotImplementedErrorclass EncoderDecoder (nn.Module):def __init__ (self,encoder,decoder ):super (EncoderDecoder,self ).__init__()self .encoder = encoderself .decoder = decoderdef forword (self,enc_x,dec_x ):self .encoder(enc_x)self .decoder.init_state(enc_output)return self .decoder(dec_x,dec_state)
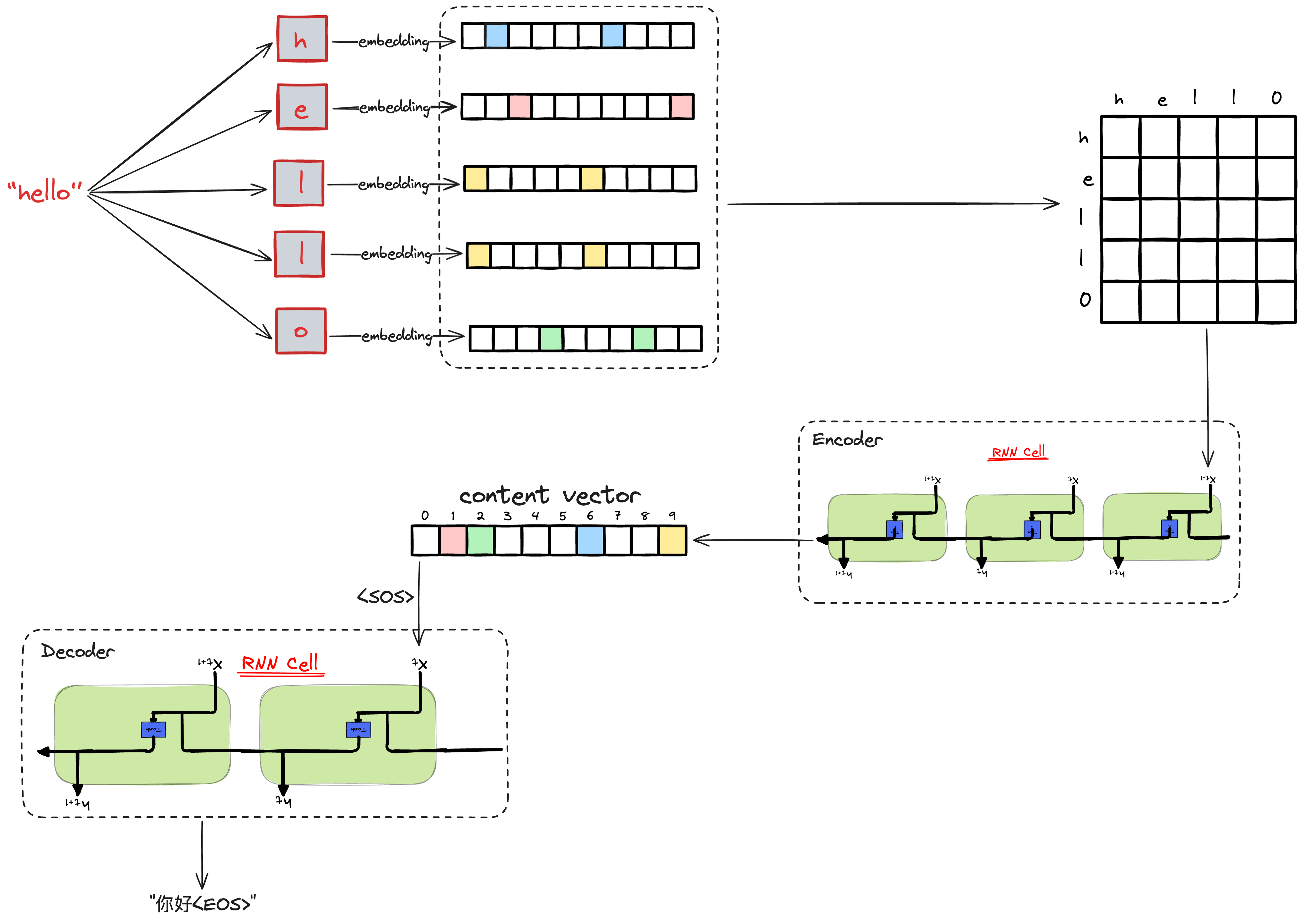
给一个英文的输入序列:“我有一只笔”,首先,编码-解码架构会将这个变长的英语序列编码为一种“状态”,然后对这种状态进行解码,一个词元接着一个词元就生成被翻译的可变长度序列输出:“I have a pen”。
1 2 3 <bos>:Begin Of Sequence(BOS)
在处理可变长度的序列时,使用 BOS 和 EOS 可以减少对 填充 (padding )的依赖,因为模型可以根据这些标记来识别序列的边界。
编码器所做的工作就是把一大段文字浓缩成一个简短的摘要,它把整个输入序列压缩成一个精华的上下文向量。然后,解码器就像一个作家,根据这个摘要重新创作出一篇完整的文章。
但是,上下文向量是固定维度的,这就导致会造成信息损失,特别是细粒度的丢失。
我们试图把一本厚厚的大百科全书的内容全部塞进一个张张小的记忆卡片里。Seq2Seq模型在做类似的事情,它需要把整个输入序列的信息压缩成一个固定大小的上下文向量。这就好比你只能记住百科全书的概要,而丢失了很多细致入微的细节。
同时,Seq2Seq模型有时候就像一个有短期记忆障碍的人,它很难回忆起很久以前发生的事情。序列虽然是变长的,但是长度过大模型往往难以捕捉到序列开始和结束之间的长期依赖关系,就像试图回忆一个长故事的每一个细节一样困难。
Teacher forcing:就像是考试时老师不断给你提示答案的一种训练方法
Exposure Bias:模型可能会过分依赖那些训练时的“提示”,而忽略了如何独立解决问题。
在Encoder-Decoder架构中,编码器和解码器之间使用一个固定长度 的“上下文向量”来传递信息,这就好比通信机制中的“压缩-解压缩”的过程。
将一张将一张 800X800 像素的图片压缩成 100KB,看上去还比较清晰。再将一张 5000X5000 像素的图片也压缩到 100KB,看上去就模糊了。Encoder-Decoder也同样面临着这种困境:当输入的信息过长时(很长的上下文),就会丢失掉一些信息。
基于这种缺陷,于是后面便创造出来Attention注意力机制。
Attention
长过程依赖:输入句子很长的时候,编码器的理解后会创建一个糟糕的总结“上下文向量”。
梯度消失/爆炸:RNN无法记住较长的句子和序列,LSTM被认为比RNN更能捕捉长依赖关系但是特定情况下容易遗忘。
那么,经过编码器创建上下文向量时,如何更小程度地保证句子中的信息损失较小呢?
于是,注意力机制应运而生。Bahdanau等人(2015)提出一个简单但优雅的想法:不仅在上下文向量中考虑所有的输入词,还可以赋予每个输入词相对重要性。
注意力就是在编码器隐藏状态中搜索一组可获得最相关信息的位置。
Attention模型最大的特点就是不再将输入序列Encoder阶段生成固定长度 的“content vector”,而是编码成一个向量的序列,解决固定长度而产生的“信息过长,信息丢失 ”问题。
这样以来,输入是序列,输出是序列,而中间的过渡变量仍然是序列。变化一小步,进步一大步 。
Attention机制就是将有限的注意力集中在重点信息上,从而节省资源,快速获得最有效的信息。
Attention的核心工作是:保持专注,关注重点 ,抛给你一张图片,关注有效信息、有效特征;同时,尽可能地减少无效信息、无效特征的干扰。
Attention的核心思想是:加权求和
从上面的建模,我们可以大致感受到 Attention 的思路简单,四个字“带权求和 ”就可以高度概括,大道至简。做个不太恰当的类比,人类学习一门新语言基本经历四个阶段:死记硬背(通过阅读背诵学习语法练习语感)-> 提纲挈领(简单对话靠听懂句子中的关键词汇准确理解核心意思)-> 融会贯通(复杂对话懂得上下文指代、语言背后的联系,具备了举一反三的学习能力)-> 登峰造极(沉浸地大量练习)。 这也如同attention的发展脉络,RNN 时代是死记硬背的时期,attention 的模型学会了提纲挈领,进化到 transformer,融汇贯通,具备优秀的表达学习能力,再到 GPT、BERT,通过多任务大规模学习积累实战经验,战斗力爆棚。 要回答为什么 attention 这么优秀?是因为它让模型开窍了,懂得了提纲挈领,学会了融会贯通。 — — 阿里技术
受到计算机视觉的影响,我们将滤波器和感受野的思路引入注意力机制。
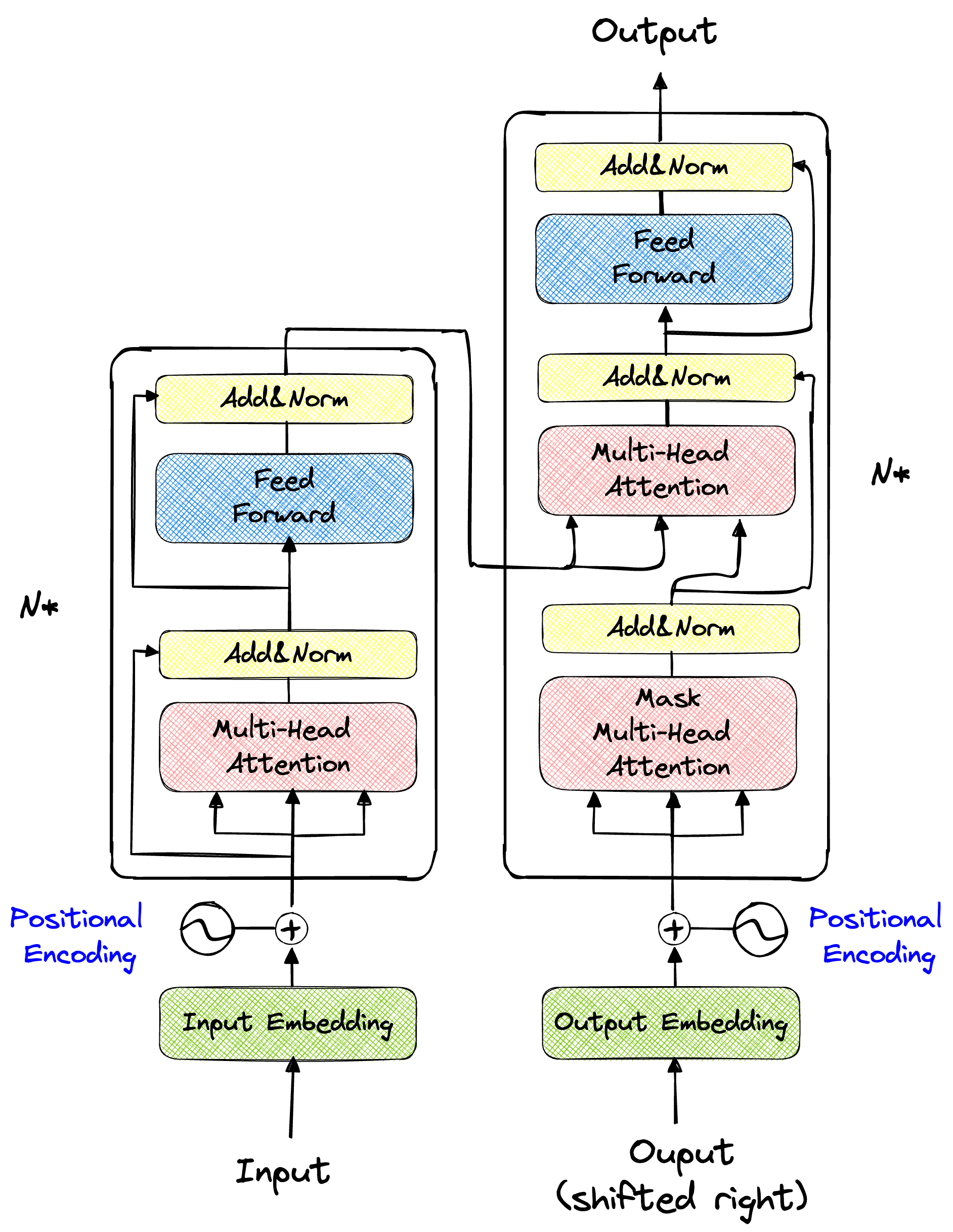
编码器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class EncoderLayer (nn.Module):def __init__ (self, d_model,ffn_hidden,num_heads,drop_prob ):'''init函数中实现对于各个层的定义''' super (EncoderLayer,self ).__init__()self .attention = MultiHeadAttention(d_model=d_model, num_heads=num_heads)self .norm1 = LayerNormalization(parameters_shape=[d_model])self .dropout1 = nn.Dropout(p=drop_prob)self .ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)self .norm2 = LayerNormalization(parameters_shape=[d_model])self .dropout2 = nn.Dropout(p=drop_prob)def forward (self,x ):self .attention(x,mask=None ) self .dropout1(x) self .norm1(x + residual_x) self .ffn(x) self .dropout2(x) self .norm2(x + residual_x) return xclass Encoder (nn.Module):def __init__ (self,d_model,ffn_hidden,num_heads,drop_prob,num_layers ):super (Encoder,self ).__init__()self .layers = nn.Sequential(*[EncoderLayer(d_model,ffn_hidden,num_heads,drop_prob)for _ in range (num_layers)])def forward (self,x ):self .layers(x)return x
解码器
attention计算为什么要除以$\sqrt{d_k}$ ?
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 class DecoderLayer (nn.Module):def __init__ (self, d_model,ffn_hidden,num_heads,drop_prob ):super (DecoderLayer,self ).__init__()'''init函数中实现对于各个层的定义''' self .self_attention = MultiHeadAttention(d_model=d_model,num_heads=num_heads)self .norm1 = LayerNormalization(parameters_shape=[d_model])self .dropout1 = nn.Dropout(p=drop_prob)self .encoder_decoder_attention = MultiHeadCrossAttention(d_model=d_model,num_heads=num_heads)self .norm2 = LayerNormalization(parameters_shape=[d_model])self .dropout2 = nn.Dropout(p=drop_prob)self .ffn = PositionwiseFeedForward(d_model=d_model,hidden=ffn_hidden,drop_prob=drop_prob)self .norm3 = LayerNormalization(parameters_shape=[d_model])self .dropout3 = nn.Dropout(p=drop_prob)def forward (self, x, y, decoder_mask ):self .self_attention(y,mask=decoder_mask) self .dropout1(y) print ("DROP OUT 1" )self .norm1(y + _y) print ("ADD + NORM 1" )self .encoder_decoder_attention(x,y,mask=None ) self .dropout2(y) print ("DROP OUT 2" )self .norm2(y + _y) print ("ADD + NORM 2" )self .ffn(y) self .dropout3(y) print ("DROP OUT 3" )self .norm3(y + _y) print ("ADD + NORM 3" )return y class SequentialDecoder (nn.Sequential):def forward (self, *inputs ):for module in self ._modules.values():return yclass Decoder (nn.Module):def __init__ (self, d_model,ffn_hidden,num_heads,drop_prob,num_layers=1 ):super (Decoder,self ).__init__()self .layers = SequentialDecoder(*[DecoderLayer(d_model, ffn_hidden, num_heads, drop_prob)for _ in range (num_layers)])def forward (self, x, y, mask ):self .layers(x,y,mask)return y
注意力机制 点积注意力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 def softmax (x ):return (np.exp(x).T / np.sum (np.exp(x), axis=-1 )).Tdef scaled_dot_production_attention (q,k,v,mask=None ):''' 实现点积缩放注意力机制 输入: q: query k: key v: value mask = None 输出: out: attention * value attention: attention score ''' 1 ] 1 ,-2 )) / math.sqrt(d_k) print (f"scaled.size() : {scaled.size()} " )if mask is not None :print ("---ADDing MASK---" )1 ) return values, attention
多头注意力 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 class MultiHeadAttention (nn.Module):'''多头注意力机制的实现''' ''' MultiHeadAttention input: input_dim: 输入维度 d_model: 模型维度 num_heads: 注意力头数量 MultiHeadAttention output: attention: 注意力分数 output: attention * v ''' def __init__ (self,d_model,num_heads ):super (MultiHeadAttention,self ).__init__()self .d_model = d_model self .num_heads = num_heads self .head_dim = d_model // num_heads self .qkv_layer = nn.Linear(d_model, 3 * d_model) self .linear_layer = nn.Linear(d_model,d_model) def forward (self,inputs,mask=None ):print ("===MultiHeadAttention===" )print (f"x.size() = :{inputs.size()} " )self .qkv_layer(inputs) print (f"qkv size() = : {qkv.size()} " )self .num_heads,3 * self .head_dim) print (f"qkv reshape size() = : {qkv.size()} " )0 ,2 ,1 ,3 ) print (f"qkv permute size() = : {qkv.size()} " )3 ,dim = -1 ) print (f"q,k,v size() = : {q.size()} " )None ) print (f"attention size() = : {attention.size()} " )self .num_heads * self .head_dim) print (f"values size() = : {values.size()} " )self .linear_layer(values) return out
位置编码 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 class PositonalEncoding (nn.Module):''' PositionalEncoding input: d_model: max_sequence_length: PositionalEncoding output: PE: A matrix with positional score ''' def __init__ (self, d_model,max_sequence_length ):super (PositonalEncoding,self ).__init__()self .max_sequence_length = max_sequence_lengthself .d_model = d_modeldef forward (self ):0 ,self .d_model,2 ).float ()pow (10000 ,even_i/self .d_model)self .max_sequence_length).reshape(self .max_sequence_length,1 )2 )1 ,end_dim =2 )return PE
前向传播网络 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 class PositionwiseFeedForward (nn.Module):def __init__ (self, d_model, hidden, drop_prob=0.1 ):super (PositionwiseFeedForward, self ).__init__()self .linear1 = nn.Linear(d_model, hidden) self .linear2 = nn.Linear(hidden, d_model) self .relu = nn.ReLU()self .dropout = nn.Dropout(p=drop_prob)def forward (self, x ): print ("===FeedForward===" )self .linear1(x) print (f"x linear1 size() = : {x.size()} " )self .relu(x) self .dropout(x) self .linear2(x) print (f"x linear2 size() = : {x.size()} " )return x
代码复现 机器翻译任务实践