Agentic RAG with LlamaIndex
传统RAG
作为一个首次接触RAG的开发者,简单理解RAG就是给LLM外挂一个知识库。
可笑的是记得第一次开组会给两位导师将MMLMs RAG System的综述博客,讲完以后导师问我如何通俗理解RAG,能不能举一个例子。我停顿了3秒,尴尬地说讲不出来。
讲不出实际的应用案例,说明你对这个领域内的知识、方法还不够理解。
老师随后说:LLM知道杨桂淼是谁吗?我说:不知道。老师接着说:如何事先已经把杨桂淼的基本信息都告诉了LLM,然后你在针对杨桂淼对LLM进行提问,那它可以回答出你的问题吗?我说:应该可以了。确实,外挂一个数据库,里面存放着所有有关杨桂淼信息的网页,当我query杨桂淼的相关问题时,LLM根据知识库返回的信息进行生产响应,这就是RAG。
RAG最核心的思想:给LLM补充外部知识以提高生成质量
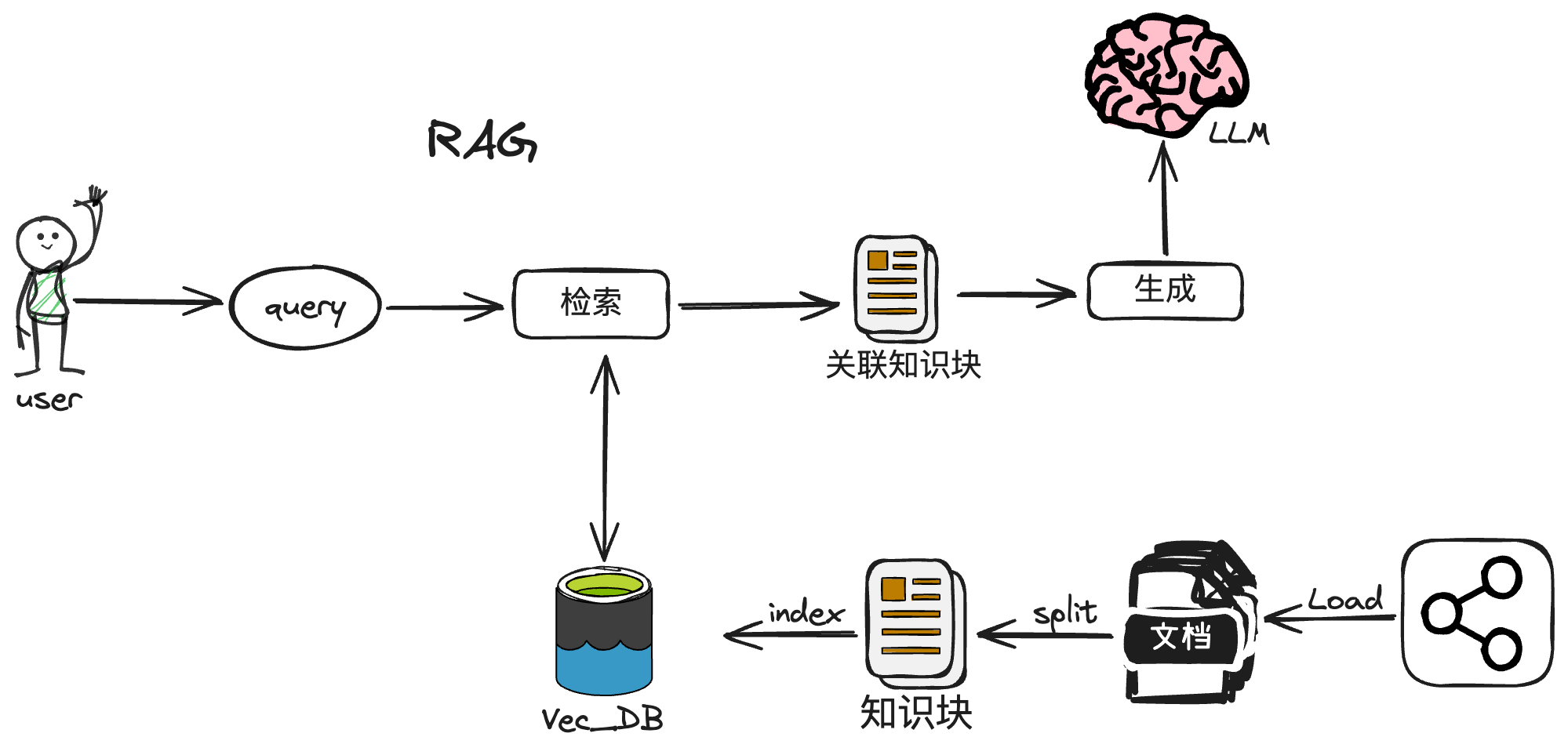
RAG应用整体上划分为两大阶段:
- 数据索引:知识-加载-分割-嵌入-索引
- 数据查询:根据索引进行检索前处理-检索-检索后处理-生成
RAG pipeline主要包括三大组件:
- 外部知识源
- 提示模版
- 生成模型
微调与RAG的区别
还是以一个例子说明
如果把LLM比做一个优秀的学生正在参加一门考试,微调与RAG的区别如下:
RAG:考试过程中给他提供这门课的全部参考资料,要求他现做现用,并争取写出答案
微调:在考试前一天对他进行辅导,让他成为某个领域/学科的专家,然后再去参加考试
RAG与具有理解超长上下文能力的LLM
大模型的上下文窗口(content window)正在以不可思议的速度增大,在超长上下文中精确检索出特定位置的某个事实性知识(大海捞针的能力)也带来了一个争议性话题:如果未来能够把几百个文档一股脑式地全部丢进大模型的上下文窗口,并且大模型能够在其中检索出事实性知识,那么我们还有必要做外部索引与检索给大模型进行知识外挂吗?
RAG的核心功能仍然是检索。事实上,大量实验测试表明,受限于主流LLM所依赖的底层Transformer架构的基本原理,当前理解超长上下文的能力并不像宣传的那样出色。
RAG与具有理解超长上下文能力LLM之间的trade-off是相辅相成、取长补短式发展的,不应该是谁取代谁。
RAG演化三范式
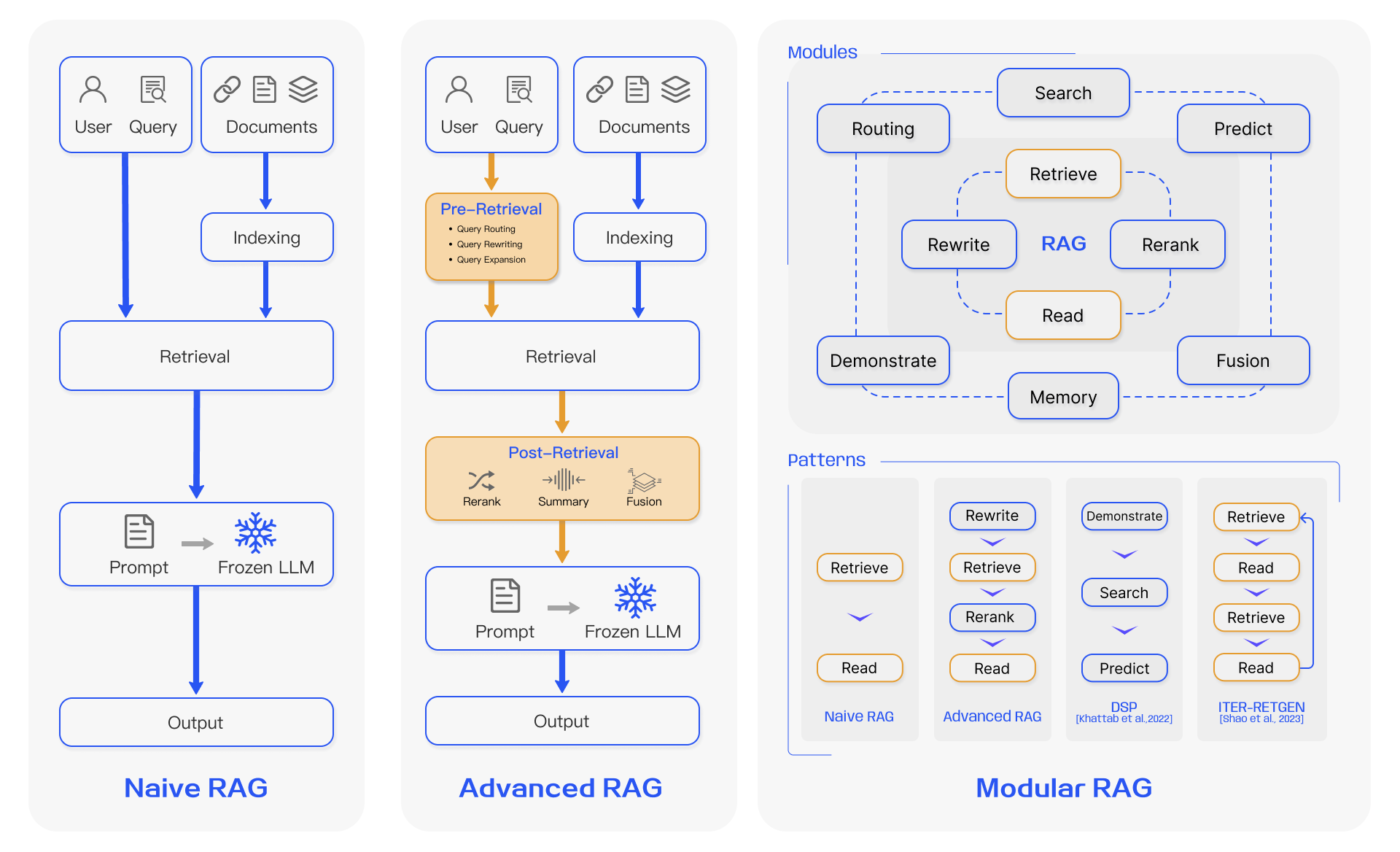
Naive RAG
Naive RAG中包含最基本的三个阶段:索引、检索、生成,是基本的链式结构。
Advanced RAG
Advanced RAG在Naive RAG的基础之上,增加了Pre-Retrieval和Post-Retrivel两个过程。
Pre-retrieval process:这个阶段主要关注的任务是优化索引结构和初始查询。优化索引的目标是提高被索引内容的质量,查询优化是使用户初始问题更加清晰并适用于检索任务。
Post-Retrieval Process:这个阶段的主要任务包括chunk重排和内容压缩。重排检索信息取重定位最相关的内容对于边缘提示是关键策略。将所有相关文档全部喂给LLM会造成信息过载,聚焦最有用的信息并突出关键信息段压缩文本。
Modular RAG
改变了前两种模式的链式结构,转而模块化结构。增加了相似度检索的search module,通过微调重定义了retriever。同时支持序列化处理和end-to-end端到端的处理
Agentic RAG
Agentic RAG describes an AI agent-based implementation of RAG,the core of Agentic RAG is Agent.
Agentic RAG—your super-smart digital library assistant!
主动式RAG是基于AI agent的RAG实现,将AI agent 整合到RAG pipeline中,编排组件以执行简单的信息检索任务和生成之外的操作,以克服non-agentic pipeline的限制。
Agentic RAG更典型的是在检索组件的pipeline中使用agents。特别的,检索组件通过使用可访问不同检索器工具(tools)的检索agetns而成为agentic。
Agentic RAG应用推理的检索场景:
- Decide whether to retrieve information or not
- Decide which tool to use to retrieve relevant information
- Formulate the query itself
- Evaluate the retrieved context and decide whether it needs to re-retrieve.
Agentic RAG的主要工作流程:
Document Processing—Creating Embedings—Indexing—Retrieval—Agent based Reasoning—Generation
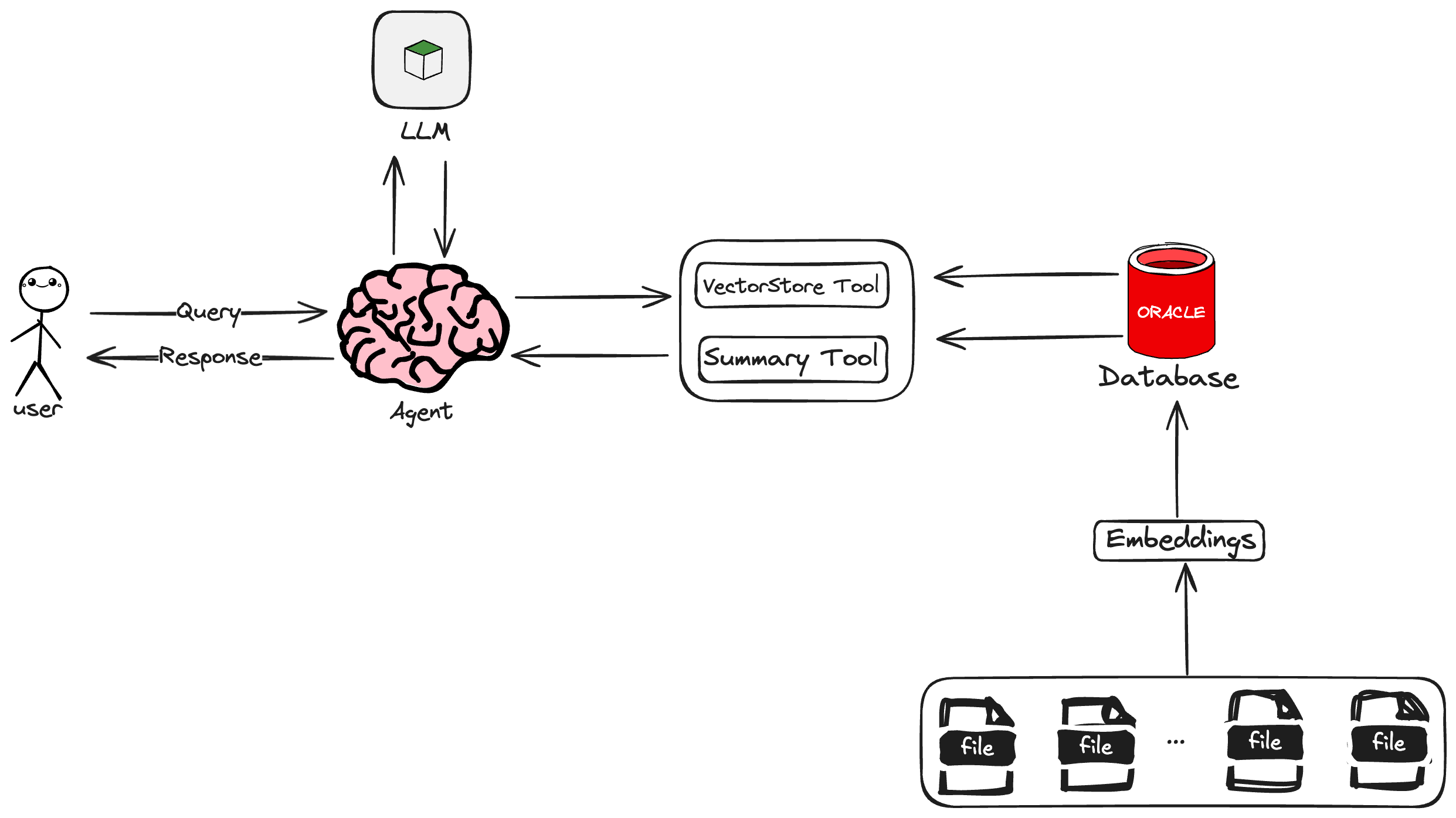
Router Engine
在基础的RAG pipeline中,LLM仅仅用于整合生成答案。而在Agentic RAG中,LLM会被作为Agent使用在检索、增强、生成的各个阶段。
Routing in the RAG system navigates through diverse data sources, selecting the optimal pathway for a query, whether it involves summarization, specific database searches, or merging different information streams. —RAG:A survey
Tool
检索组件的工具选择:
- Vector search Engine
- Web search
- Calculator
- software(Email、chat programs)
Agentic RAG属于RAG范式中的第三阶段:Modular RAG。
从文档的读取开始,处理流程基本上都是模块化层层封装好各个组件,已实现查询引擎的功能。
无论是引擎模块还是预测模块,最终都是将底层方法层层封装为工具方法,在将所有的工具方法整合为最终的引擎模块。
文档读取-文档分割-索引建立VectorIndex(nodes)-使用索引作为查询引擎index.as_query_engine-调用QueryEngineTool方法将查询引擎进行工具封装-将工具整合为LLM的predict_and_call模块进行生产应答
Implementing a Basic Multi-Document Agentic RAG
博客链接:https://www.analyticsvidhya.com/blog/2024/09/multi-document-agentic-rag-using-llamaindex/
Setup
必要的库:
1 | |
加载数据
首先将文档转换为nodes插入到DocumentStore数据库中。