Multimodal RAG and Prompt Compression
Multimodal RAG与Prompt compression再梳理
Multimodal RAG System Work Flow
多模态RAG的完整工作流如下图所示:
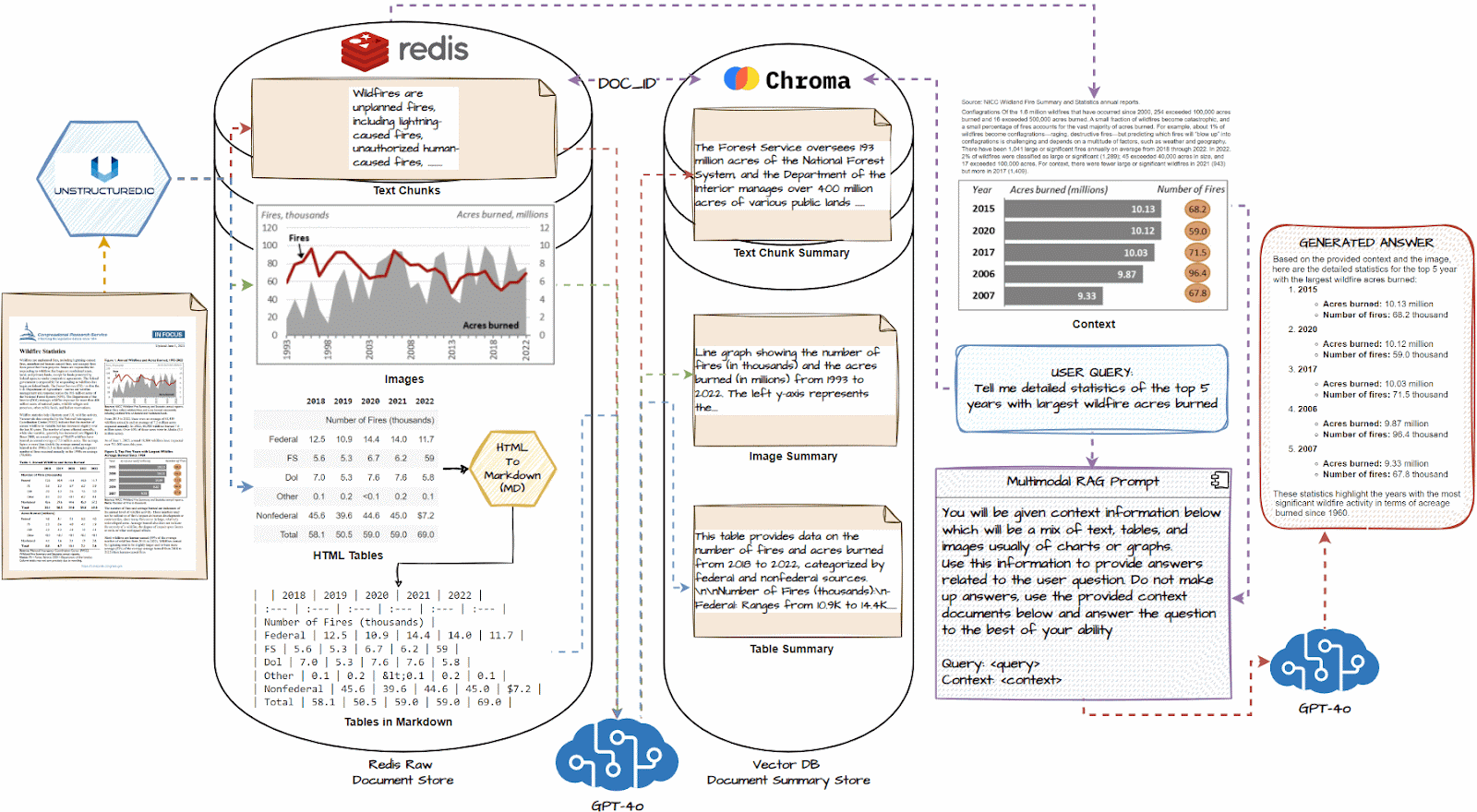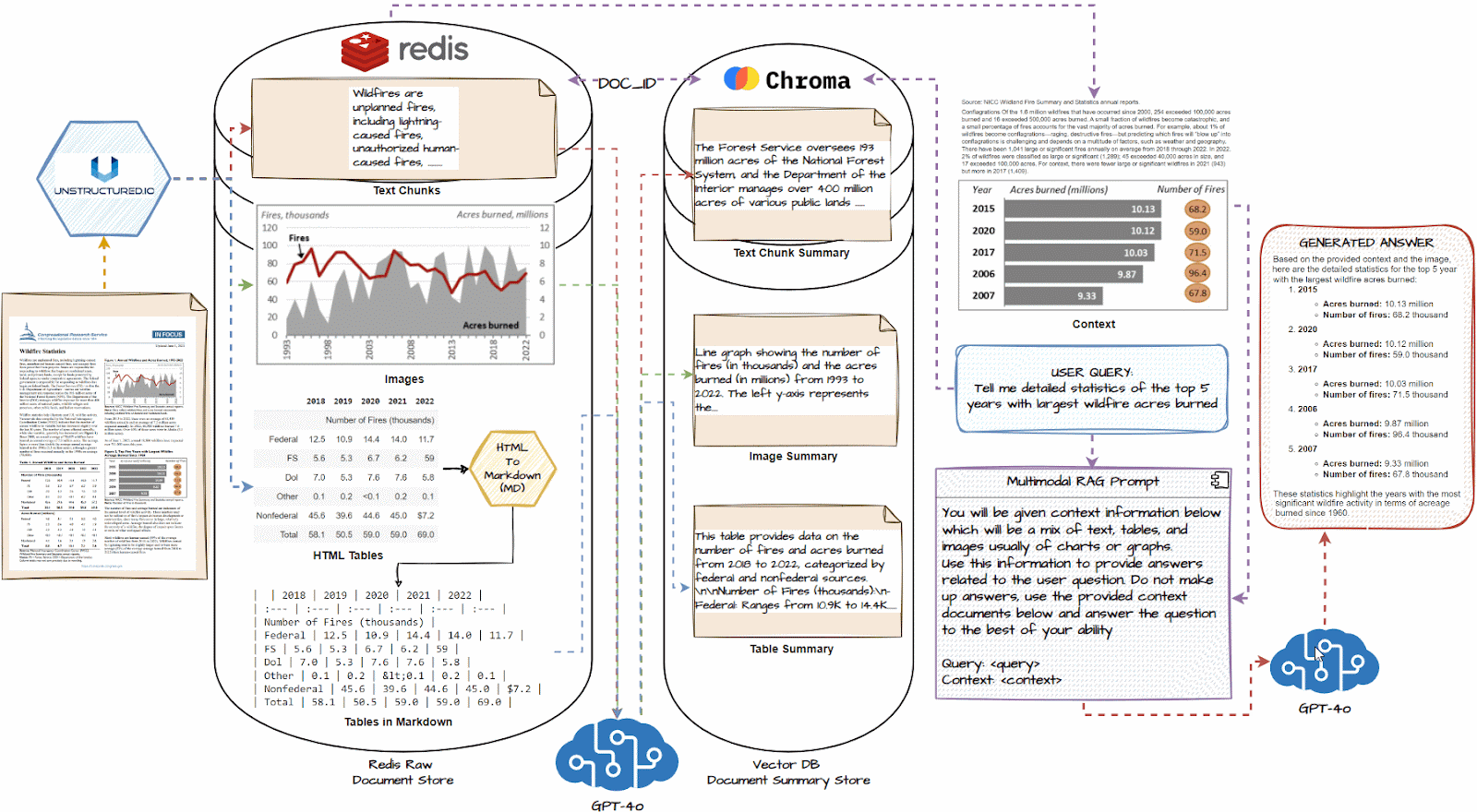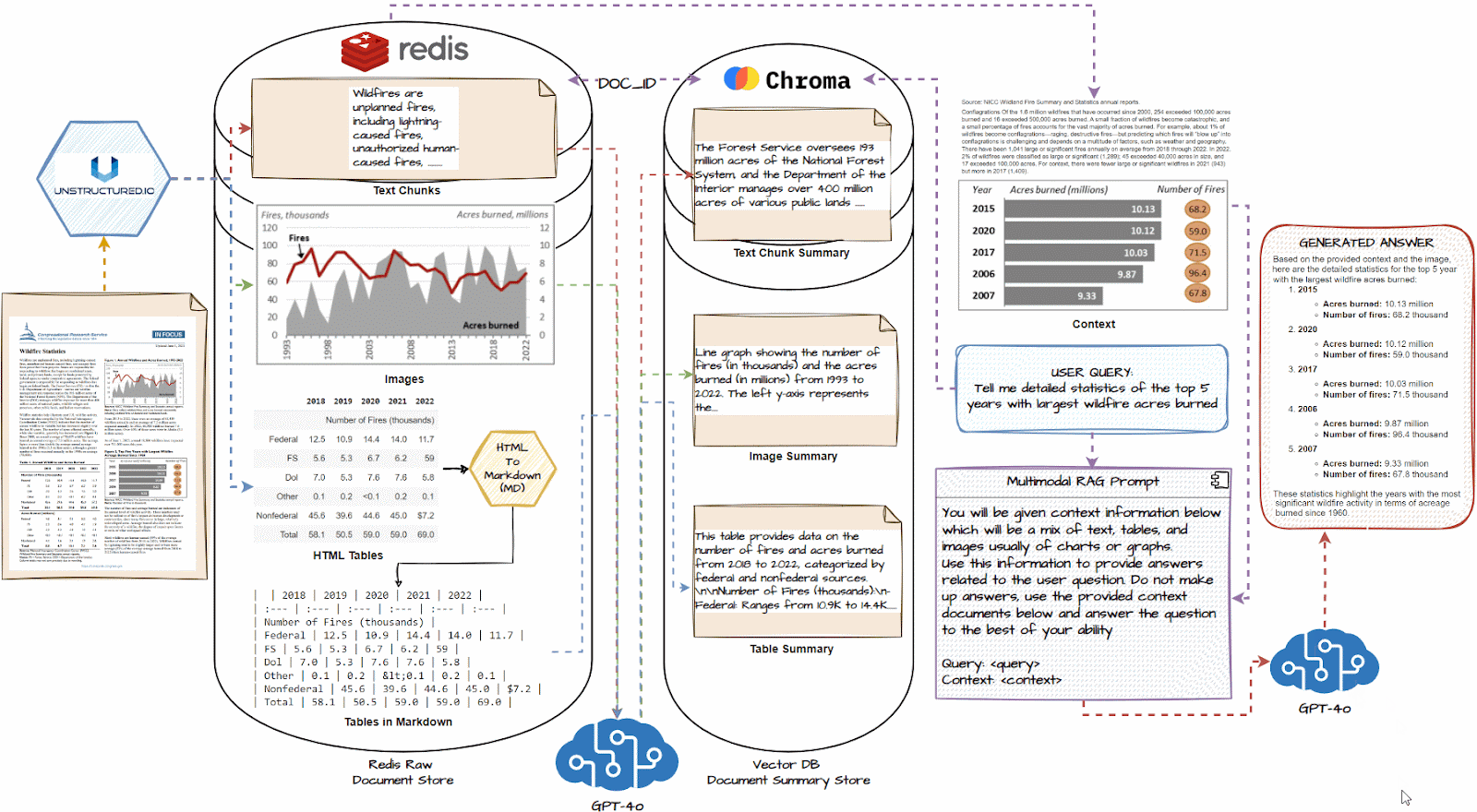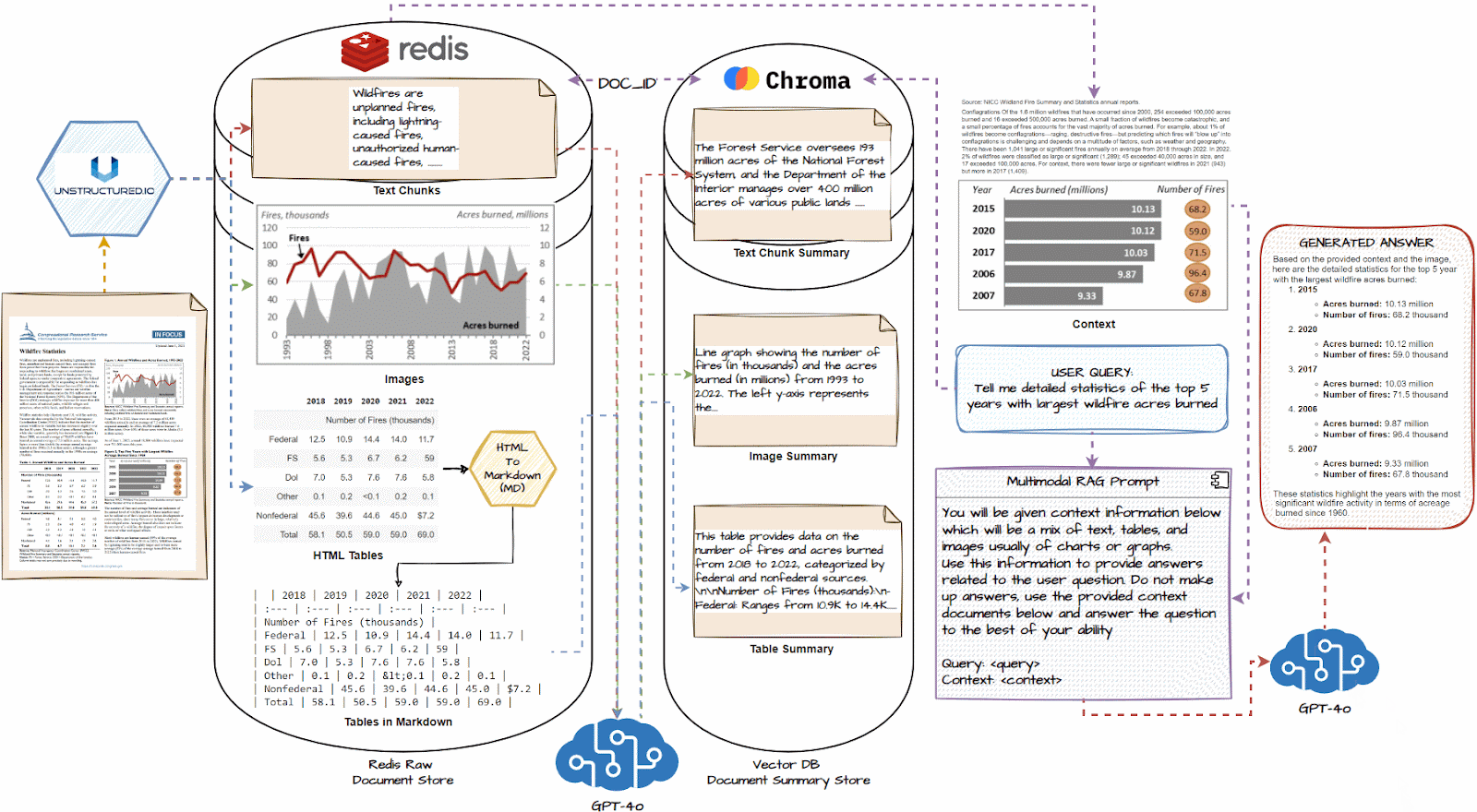
再次梳理一遍多模态RAG系统的工作流程:
1.多模态信息输入—2.特征提取—3.特征融合—4.信息检索—5.上下文构建—6.生成答案
1.加载所有文档,并使用类似unstructure.io的文档加载器提取文本块、图像和表格。
2.如有必要,将HTML表格转换为markdown;他们通常对LLM非常有效
3.将每个文本块、图像和表格传递到GPT-4o等多模式LLM中,并获得详细的摘要。
4.将摘要存储在向量数据库中,将原始文档片段存储在Redis等文档数据库中
5.使用多向量检索器使用公共document_id连接两个数据库,以识别哪个摘要映射到哪个原始文档块。
6.将这个多向量检索系统与GPT-4o等多模态LLM连接起来。
7.查询系统,并根据与查询类似的摘要,获取原始文档片段,包括表格和图像,作为上下文。
8.使用上述上下文,使用多模态LLM生成问题的答案。
输入
多模态输入
在VQA系统中,文本+图像是常见的输入形式。
多模态RAG系统处理的是多种类型的数据,主要包括:
- 图像(Image):可以是用户上传的图片、视频帧等视觉内容。
- 文本(Text):用户的问题、描述、上下文信息等语言内容。
特征提取
图像特征提取:
- 使用预训练的卷积神经网络(如ResNet、EfficientNet)或专门的多模态模型(如CLIP、VisualBERT)提取图像特征。
- 图像特征通常表示为高维向量或特征图。
文本特征提取:
- 使用基于Transformer的模型(如BERT、RoBERTa)或其他词嵌入技术(如Word2Vec、GloVe)将文本转换为嵌入向量。
- 文本特征表示为上下文相关的向量表示。
特征融合
联合表示(Joint Representation)
将图像特征和文本特征结合成一个统一的表示,以便模型能够同时考虑两种模态的信息。
- 拼接式融合(Concatenation):
- 直接将图像特征和文本特征向量拼接在一起。
- 交互式融合(Interactive Fusion):
- 使用自注意力机制(Self-Attention)或跨注意力机制(Cross-Attention)在Transformer编码器中融合多模态特征。
- 例如,VisualBERT将图像区域特征和文本嵌入在同一序列中,通过自注意力层实现交互。
联合嵌入(Joint Embedding)
通过多模态对齐技术(如对比学习)将不同模态的特征投射到同一语义空间中,使得跨模态检索和匹配更为有效。
- CLIP(Contrastive Language-Image Pretraining):
- 将图像和文本通过独立的编码器映射到共同的嵌入空间,通过对比损失优化使相关的图像和文本特征靠近,不相关的则远离。
- BLIP/BLIP2
信息检索
检索模块
基于融合后的多模态特征,从知识库或文档库中检索与输入相关的信息。
- 相似度计算:
- 计算输入特征与知识库中每个文档或片段的相似度(如余弦相似度)。
- 索引与搜索:
- 使用高效的向量索引技术(如FAISS、Annoy)加速大规模相似度搜索。
检索结果过滤与排序
- 过滤:
- 排除与查询不相关或低质量的检索结果。
- 排序:
- 根据相似度得分对检索结果进行排序,选取最相关的若干条信息作为生成答案的依据。
上下文构建
上下文整合
上下文的内容:检索到的相关信息与原始输入(图像和问题文本)进行整合后的内容
- 上下文增强:
- 将检索到的文本信息与输入问题结合,提供更丰富的背景知识。
- 图文结合:
- 将检索到的文本信息与图像特征共同输入生成模型,辅助生成更准确的答案。
Prompt Compression(提示压缩)
为了提高模型处理效率和响应速度,对输入提示进行压缩,将多模态信息以更紧凑的形式传递给生成模型。
- 联合特征表示:
- 使用预训练模型生成的联合嵌入向量作为压缩后的提示。
- 模板化设计:
- 设计高效的prompt模板,将图像和文本信息结构化地嵌入其中。
答案生成
生成模块
利用生成模型(如GPT、Mistral)基于整合后的上下文信息生成自然语言答案。
- 自回归生成(Autoregressive Generation):
- 模型逐步生成答案,每一步依赖于之前生成的内容和上下文。
- 条件生成(Conditional Generation):
- 生成过程受到输入条件(如问题文本和图像特征)的约束,确保生成内容与输入相关。
生成优化
- 多样性与一致性:
- 通过调整生成参数(如温度、顶层采样)控制答案的多样性和一致性。
- 格式控制:
- 使用特定的prompt模板引导生成内容的格式和风格。
Prompt的具体形式
Multimodal RAG System博客里面的Prompt格式
博客中prompt构建函数如下:
1 | |
经过multimodal_prompt_function处理后的信息被整合为一个messages列表:messages = [image_message,text_message]。
构建出的Prompt主要包含两部分:图像信息+文本信息
假设检索到的上下文包含两个文本段落和一张图像,用户问题为“Tell me detailed statistics of the top 5 years with largest wildfire acres burned”
1 | |
EchoSight论文里的Prompt格式
最终的Prompt格式
Context + Question:prompt 格式通常包括上下文和问题:
1 | |
具体例子:
1 | |
带图像的prompt
1 | |
可以将图像特征转化为文本描述:
1 | |
也可以将图像通过特征提取模型转换为特征向量,以特定格式嵌入到 prompt 中:
1 | |
图像+文本 Prompt 格式-联合表示形式
将图像特征和文本信息结合成一个联合输入,可以使用 CLIP 这样的多模态模型将图像和文本映射到相同的嵌入空间
1 | |
CLIP、VisualBERT、FLAVA等模型是基于 多模态数据联合训练 的。这些模型已经通过海量的图像-文本配对数据进行训练,能够在 文本 和 图像 之间建立语义连接。
Transformer模型的 自注意力机制(Self-attention)能够有效地对输入的不同部分进行加权,理解其中的关系。当我们输入 图像特征 和 问题文本 时,模型通过注意力机制结合这两部分信息,从而产生推理。
GPT、Mistral等非常擅长处理长文本和复杂的上下文关系。通过 自回归生成 或 条件生成,模型会基于已知的上下文信息生成答案。
RAG链构建
RAG链构建如下:
1 | |
- 使用
itemgetter从输入数据中提取'input'(用户的问题)。 - 通过
RunnableLambda运行multimodal_prompt_function,将提取的context和question传入,生成多模态prompt。 - 生成的prompt传递给
chatgpt模型(假设为GPT-4模型的实例)进行回答生成。 - 使用
StrOutputParser将模型生成的回答解析为字符串格式。
信息检索模块构建如下:
1 | |
- 使用
itemgetter从输入数据中提取'input'(用户的问题)。 retriever_multi_vector使用多向量检索技术(如基于CLIP的多模态向量检索)从知识库中检索与查询相关的文档和图像。- 通过
RunnableLambda(split_image_text_types)将检索到的内容分为文本和图像两类,便于后续处理。
整合RAG链与检索模块:
1 | |
- 使用
RunnablePassthrough.assign将retrieve_docs的输出赋值给context键。 - 使用
.assign将先前定义的multimodal_rag链赋值给answer键。 - 通过这种方式,最终的
multimodal_rag_w_sources链能够同时处理检索到的上下文和生成的答案。