EchoSight论文研读复现
EchoSight: Advancing Visual-Language Models with Wiki Knowledge
Advancing Visual-Language Models
推进VLM,推进点在哪里?
现有的视觉语言模型VLM(GPT-4V、Gemini、LLaVA、Phi-3-Vision)已经可以很好的解决Standard VQA任务,表现出来较强的图像分析和较准确的答案生成。
但是现有的VLM在KB-VQA(知识型视觉问答)任务上仍然存存在的问题:幻觉、不存在的文本与内部偏见和良好的检索机制。
本文的推进点就是设计并实现了一种新型的多模态RAG框架:EchoSight,这种方法显著增强了检索到的文本知识和视觉内容之间的对齐,从而提高了E-VQA和InfoSeek等基准测试的性能。
Information Retrieval+LLM = RAG
Information Retrieval+MLLM = M-RAG
创新点
EchoSight首先通过使用visual-only information的方法搜索wiki文章
根据相关性结合text-image query对候选文章进行重排序
整合了一个RAG的检索-重排过程
主要贡献
提出了MLLM RAG框架:EchoSight,可以回答需要细粒度的百科全书知识的视觉问题
采取了一种retrieval-and-reranking scheme方法提升了检索效果
在Encyclopedic VQA和InfoSeek数据集上进行实验均取得的结果均优于现有的VLMs和其他RAG架构
Method
检索增强VQA的问题定义->retrieval-and-reranking->答案生成
EchoSight的整体架构图如下所示:
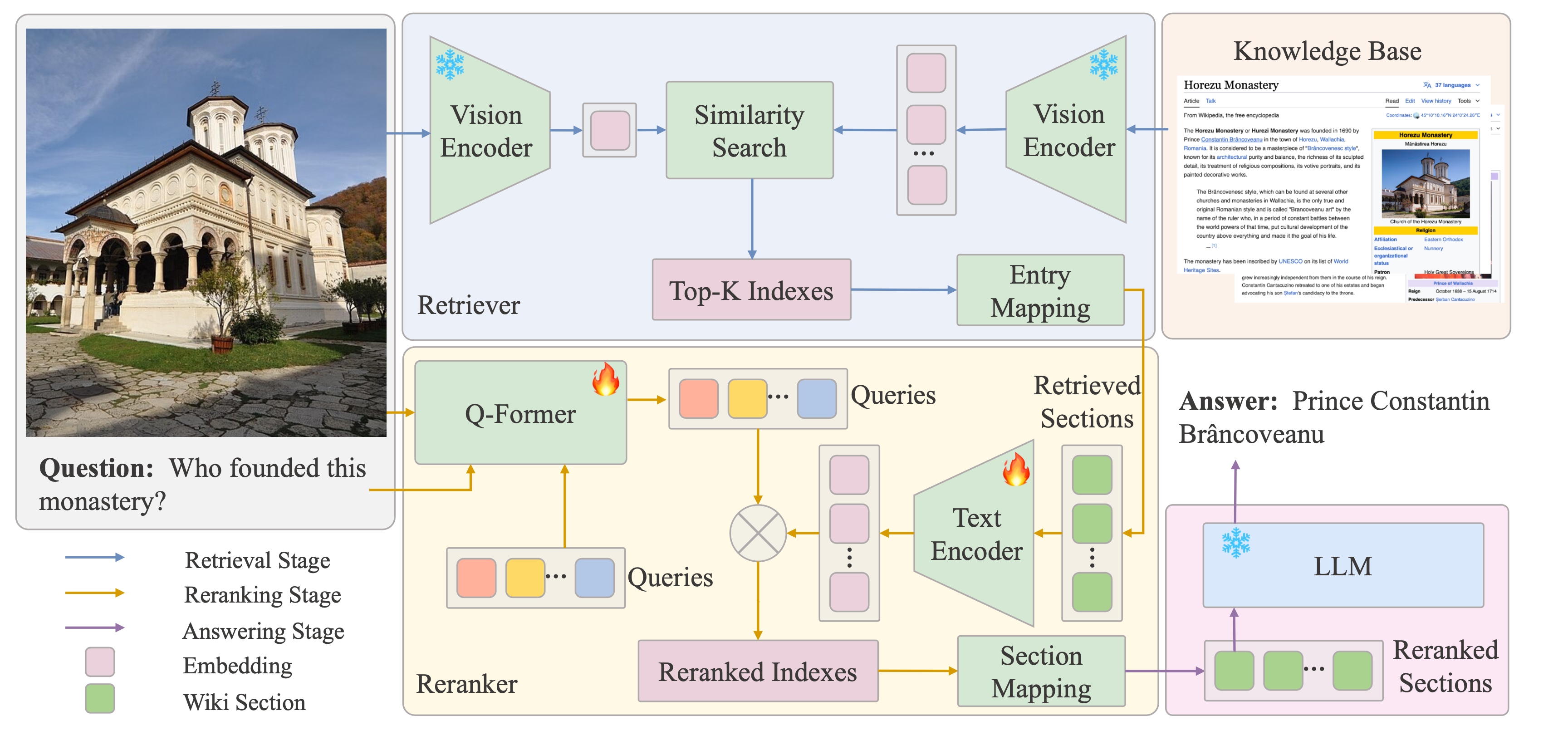
4个主要组成
an external knowledge base(KB): Wiki
a retriever: $S_\Omega$
a reranker: $S_r^\text{sec}$ + $sec_{vl}$
an answer generator: LLM
Problem Formation
输入:一张参考图片和一个自由形式的文本型问题
输出:答案
目标:建立一个视觉问答系统
辅助:接入外部知识源
知识源是一百万规模的实体文章及与它们相关的来自维基百科网页的图像
$$
B = {(a_{1},I_{1}),(a_{2},I_{2})…(a_{n},I_{n})}
$$
整个过程从检索器开始,利用参考图像过滤并提取与相似图像有关的KB文档实体,之后重排器会
获取候选实体并使用它们的文本内容来重新排序,基于参考图片和文本问题之间的相关性;最后
将重排KB实体“喂”给答案生成器产生最终答案。
Retrieval and Reranking
这一阶段的主要目标就是根据给定的参考图像和文本问题从大规模外部数据集中识别相关实体。
Visual-only Research
纯视觉搜索识别视觉上与查询图像相似的候选对象。Knowledge Base中存储格式:“image-article” pairs,优化图片检索是至关重要的。
方法:将所有图片转换成向量,利用cosine similarity评估度量与参考图片的相似性。
$$
S_\Omega={s_i=\left\langle\frac{v_r}{||v_r||}\cdot\frac{v_i}{||v_i||}\right\rangle,i=1,\dots,n}
$$
$v_{r}$表示参考图片的嵌入;$v_{i}$表示数据库图像的嵌入。
FALSS库进行向量搜索,并保留Top-k最佳匹配图像和对应的文章实体。$\mathcal{E}_v={(a_1,I_1),\ldots,(a_k,I_k)},k\ll n$
Multimodel Reranking
评估视觉和文本信息以重新排序检索实体。集成整合包含文本和视觉输入,来自多模态查询和top-k个检索得到的wiki文章实体,
确保相关性最高的文章排在顶部。
方法:运用Q-Former架构从文本问题和参考图像中提取多模态信息,生成32query tokens。
$$
z_m^i=\text{Q-Former}\left(I_\text{ref},Q\right)^i
$$
${z_m^i}$记为参考图片$I_{ref}$和文本问题$Q$的第$i_{th}$个query token嵌入。
在候选文章中,本论文将候选的wiki文章切分成以文章标题为前缀的sectioins:${sec_1^i,sec_2^i,\dots,sec_p^i}$。使用Q-Former文本编码器对sections进行编码,使用BLIP-2的权重初始化Q-Former,并微调除视觉编码器之外的所有参数。
重排得分:
$$
S_r^\text{sec}=\max_{1\leq i\leq N_q}\left(\sin(z_m^i,z_s^\text{sec})\right)
$$
这种方法计算了在多模态query token嵌入和wiki文章section的token嵌入之间最高的成对相似性,每一个多模态query token嵌入${z_m^i}$都来自“img-question”对。
计算完重排得分后,最后一步是进行多模态重排,reranker将前一阶段视觉相似度得分和重排得分合成一个加权和:
$$
\begin{aligned}\sec_{vl}&=\arg\max_{\text{sec}\in a}(\alpha\cdot S_v^\text{sec}+(1-\alpha)\cdot S_r^\text{sec})\end{aligned}
$$
$sec_{vl}$表示的是经过reranker得到的最高排序实体section,注意这里是section而不是article。${\alpha}$是权重参数用来平衡视觉相似度得分$S_v^\text{sec}$和重排得分$S_r^\text{sec}$。
Note:$S_v^\text{sec}$有别于前文中的$S_\Omega$,它是在visual-only搜索阶段使用sec所属的wiki条目中的最佳匹配图像来计算的。
Reranking Training
前文中使用对比学习框架完成了硬负采样,负样本的选取是从视觉相似但是内容有别的例子中选取的,以至于最初的visual-only检索并不成功。训练重排器的目的就是为多模态queries选取最相关的文章以提高系统的整体的准确率和有效性。
训练的损失函数定义为:
$$
\mathcal{L}=-\log\frac{\exp(\max_{1\leq i\leq N_q}\sin(z_m^i,z_s)/\mathcal{T})}{\sum_{j=1}^N\exp(\max_{1\leq i\leq N_q}\sin(z_m^i,z_s^j)/\mathcal{T})}
$$
${z_s}$是positive section嵌入,$N$是全部的正负样本数量,$\mathcal{T}$是一个控制softmax平滑分布的超参数。
Answer Generation with LLMs
一旦从KB中识别出相关条目,LLMs会整合所有的信息来生成answer,$A = LLM(sec_{vl},Q)$。LLM是答案的genertor,$sec_{vl}$是检索得到的wiki文章section,$Q$是目标问题。
Experiment
两个数据集
Encyclopedic VQA 和 InfoSeek
Encyclopedic VQA:contains 221k unique question and answer pairs each matched with (up to) 5 images, resulting in a total of 1M VQA samples
InfoSeek:comprises 1.3M visual information-seeking questions, covering more than 11K visual entities from OVEN
度量指标
关注两个度量指标:检索和问题回答。
检索衡量的是在大规模多模态知识库中检索相关文章的准确性,问题回答衡量的是对于视觉问题提供准确回答的有效性。
检索度量
本文使用标准Recall@K,Recall@K评估是否正确的文章实体出现在top-k的检索结果中。
只有当一篇文章的URL与目标URL完全匹配时,它才被认为是正确的,这使得我们的检索评估与只匹配所检索到的文章的答案内容的方法相比更加严格和精确。
问题回答的度量
E-VQA:BEM score
InfoSeek:VQA Accuracy and Relaxed Accuracy
Implementation Details
检索器
Eva-CLIP作为检索器,将参考图片和数据库图片进行视觉嵌入
重排器
重排器使用带权重LAVIS的BLIP-2
生成器
E-VQA:Mistral-7B-Instruct-v0.2
InfoSeek:LLaMA-8B-Instruct
结果
很明显,我们提出的EchoSight框架实验结果远远超过了之前的工作,甚至接近了原始E-VQA(Mensink等人,2023)在基准报告的上行结果,其中采用了两个巨大的模型,即“Google Lens”用于知识检索,PaLM用于答案生成。

消融实验
使用E-VQA数据集进行消融实验。
在检索方面,我们进行了以下分析:
(i)比较检索中不同的vision backbones
(ii)研究重新排序范围的影响
(iii)调查硬负抽样的重要性。
在最终答案生成时,我们进行了消融研究:
(i)各种语言模型的影响
(ii)在oracle设置下使用答案生成器进行实验。
Conclusion、Limitations and Future work
Conclusion:
在本文中,介绍了一种新的检索增强视觉语言系统EchoSight,用于解决基于知识的视觉问题回答(VQA)的挑战。通过改进的两阶段方法,EchoSight显示出显著的性能改善,E-VQA的准确率为41.8%,InfoSeek的准确率为31.3%。
EchoSight的成功强调了高效的检索过程和多模态信息的集成在基于知识的VQA任务中提高大型语言模型(LLMs)性能方面的重要性。
Limitations:
严重依赖检索知识源的高质量和完整性;在特定领域上表现欠佳
多模态重排阶段需要消耗大量计算资源,耗时长,不利于实时应用
Future work:
优化计算开销能不能和prompt压缩和检索得分结合起来?
提高知识源质量
优化多模态计算开销
复现代码的实验环境
GPU:Nvidia RTX 4090
显存:16GB
内存:50GB
Git拉取源码仓库
1 | |
model/文件夹下存放着模型源代码
dataset/文件夹下存放着wiki知识源
scripts/文件夹下存放着训练脚本shell文件
requirements.txt文件存放着项目所需要的第三方库
app.py是前端检索的demo程序
Conda 创建虚拟环境
1 | |
下载数据集
Enclyclopedic-VQA
Infoseek
将数据集上传到云服务器
使用xftp传输
模型训练
EchoSight 的多模态重排序器使用 Encyclopedic-VQA 数据集和相应的 2M 知识库进行训练。要训练多模式重新排序器,请在更改必要的配置后运行 bash 脚本:
修改配置文件参数路径:
1 | |
–train_file:训练数据文件的路径。 训练文件应与 Encyclopedic-VQA 提供的格式相同。
–knowledge_base_file:JSON 格式的知识库文件的路径。 格式应与Encyclopedic-VQA 的格式相同。
–negative_db_file:用于训练的硬负样本数据库文件的路径。
–inat_id2name:iNaturalist ID 到名称映射文件的路径。
执行脚本:
1 | |
test_reranker:
我们的重新排序模块权重可以在[Checkpoint]下载,要使用经过训练的模型进行推理,调整必要的参数后运行提供的 test_reranker.sh脚本。
1 | |
–test_file:测试文件的路径。
–knowledge_base:知识库 JSON 文件的路径。
–faiss_index:用于高效相似性搜索的 FAISS 索引文件的路径。
–save_result_path:保存结果 json 文件的路径。
重点关注的问题
- prompt的具体格式是啥样的?-》看代码,做这一方面一定要对格式有一个清楚的了解
- MLLMs RAG的prompt(最后生成答案前的一步)
- 重排的方法有哪些?可以调研一下