经典卷积神经网络复现
基于pytorch将经典的卷积神经网络架构复现一下
卷积神经网络基础知识
数据又表格数据过渡到图像的像素数据,网络结构由全连接的多层感知机过渡到卷积结构。
卷积神经网络就是将空间不变性这一概念系统化,基于这个模型使用较少的参数学习有用的表示。

卷积神经网络的输入:n * n * 3的图片向量
卷积神经网络的输出:类别标签/类别向量(经过softmax归一化后)
通道:图像一般包含3个通道/3种原色(RGB),一个颜色就是一个色彩通道。
感受野:卷积神经网络在图片上设定的区域大小
步幅:感受野在图片上移动的距离
填充:感受野在移动过程中可能会超出图片的像素范围,超出范围的地方用数字补值的方式就是填充
滤波器:让每个感受野都只有一组参数从而达到简化的方法。
卷积层:感受野+参数共享
下采样:把图像偶数列都拿掉,奇数行都拿掉,图像变成为原来的 1/4,但是不会影响里面是什么
东西。
汇聚:汇聚没有参数只是一个操作,将滤波器产生的结果进行分组后按要求汇聚(取最大/取平均)
池化层:取窗口中的最大值最为输出结果,然后滑动窗口减少其空间尺寸
LeNet-5
卷积神经网络的开山之作,1998年由LeCun Yang提出。
网络结构图
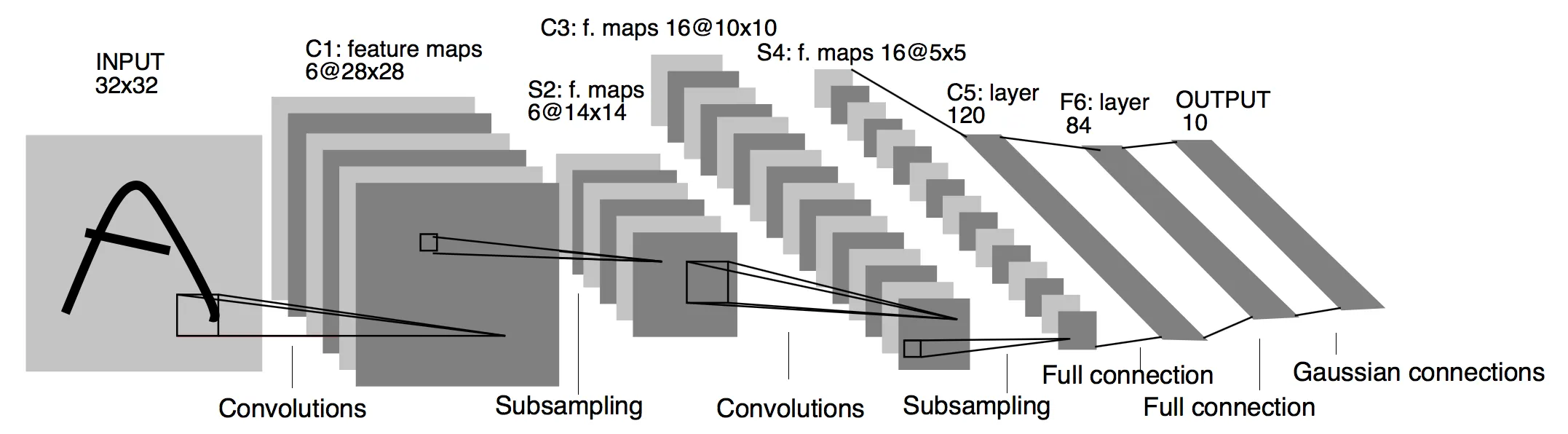
复现代码
1 | |
AlexNet
2014年ImageNet比赛的冠军
网络结构图

结构细节
卷积核大小如何确定?
虽然说目前有比较火的研究方向针对这种自动神经网络结构搜索(NAS),这些自动搜索出来的网络在常规数据集上的建模结果显示(当然是达到一定的准确度):自动搜索出来的网络中的卷积核的类别有包括各种常见的型号(3 * 3、5 * 5、7*7),且在网络中的前后排布没有规律。
nn.BatchNorm2d()的作用?
在深度神经网络中,梯度消失是一个常见的问题。BatchNorm2d通过对激活函数前添加归一化层,抑制了梯度消失的问题,从而加速了优化过程。
BatchNorm2d通过对数据的归一化处理,使得权重初始化的影响减小,无论权重的初始值如何,都可以通过归一化和仿射变换得到较好的效果。
nn.Dropout(0.5,inplace=True)的作用?
nn.Dropout模块的作用是在训练过程中随机关闭一部分神经元,以增加模型的泛化能力。通常,我们在全连接层之后应用dropout,以避免破坏卷积层中重要的空间信息。
一般建议在10%-50%之间设置dropout比例
复现代码
1 | |
VGG
2014年ImageNet比赛的亚军
网络结构图

每一个长方体“板子”就是一张图片数据的一个tensor,搭建网络的过程中关注每一块“板子”之间的变化即可。
复现代码
1 | |
VGG网络只是对网络的层书进行堆叠,并没有进行结构性的创新,不过加深网络深度确实可以提高模型效果。
GoogleNet
GoogleNet也被叫做InceptionNet,它解决了一个核心问题是选择多大的卷积核是最合适的问题。在GoogLeNet中,基本的卷积块被称为Inception块(Inception block)。

动手学深度学习:Inception块由四条并行路径组成。前三条路径使用窗口大小为1×1、3×3和5×5的卷积层,从不同空间大小中提取信息。中间的两条路径在输入上执行1×1卷积,以减少通道数,从而降低模型的复杂性。 第四条路径使用3×3最大汇聚层,然后使用1×1卷积层来改变通道数。
- 难点1是如何并行设计出网络结构?
- 难点2是并行输入输出的通道数如何计算?
网络结构图

1 | |
ResNet
2015年ImageNet比赛的冠军,通过残差模块能够成功训练出152层深度的残差网络。
设计的灵感来源于:加深神经网络的时候会出现一个Degradation,准确率上升到达饱和,在持续增加深度会导致模型的准确率下降。
假设一个比较浅的网络达到了饱和准确率,那么在它后面加上几层恒等映射层误差不会增加,也就是说更深的模型不会是模型的效果下降。恒等映射的思想就是ResNet的灵感来源。
网络结构图
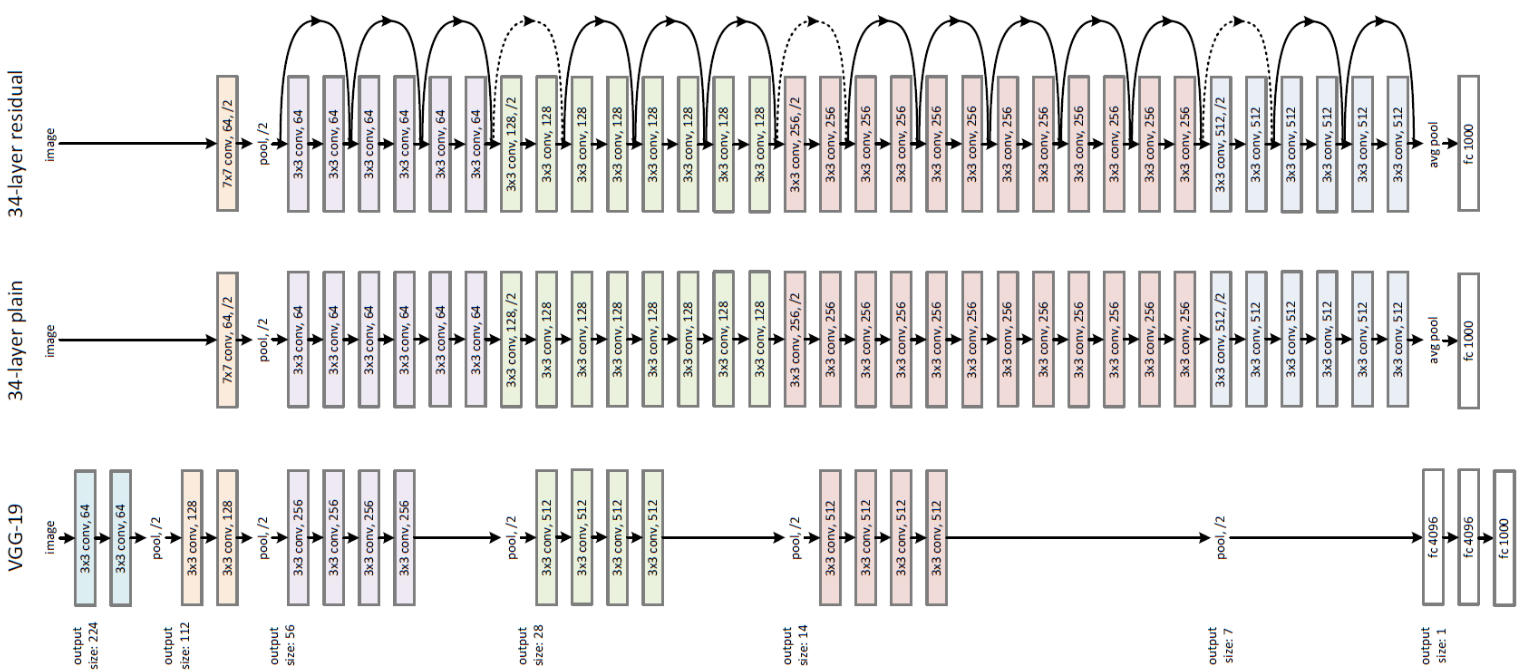
实现代码
1 | |
总结
1.卷积神经网络的基本概念一定要熟练掌握
2.对于使用pytorch搭建神经网络模型要熟练掌握代码编写的过程与逻辑
3.对于步长和填充值的计算要理解,特别是GoogleNet和ResNet的padding和stride值的计算
4.如何根据网络架构图取复现代码是理解网络结构和pytorch工具箱的结合