Multimodal RAG System Survey
A Comprehensive Guide to Building Multimodal RAG Systems
本篇博文的主要内容是对一篇综述性博客文章()的翻译阅读与总结。通过阅读本篇文章,理清楚多模态RAG的基本概念与应用场景、部署方式、工作流程。
RAG系统的优势是可以整合自身数据并增强LLM的智力,对于问题给出更多精确的回答。然而,关键的限制就是RAG系统仅仅是它仅适用于文本数据。 许多现实世界的数据本质上是多模态的,是文本、图像、表格等形式的混合。
该篇综述的主要目的就是着眼构建一个多模态的RAG系统,使用智能数据转换和多模态LLM解决混合数据格式。
传统的RAG系统
RAG系统架构通常包括:
- 数据处理和索引
- 检索和响应生成
数据处理和索引
加载文档中的文本内容->将大型文本元素拆分为较小的块->使用嵌入器模型将它们转换为嵌入->将块和嵌入存储到矢量数据库中

检索和响应生成
用户提问->文档检索->提示->LLM->回答
从向量数据库中检索与输入问题相似的相关文本文档块,然后将问题和上下文文档块发送到LLM以生成人类。

传统RAG系统的限制
- 无法获悉实时数据
- 系统仅会利用好我们自身向量数据库中的数据
- 大部分RAG系统仅仅致力于文本数据的检索和生成
- 传统的LLMs 仅仅处理文本内容去生成回答
- 无法利用多模态数据进行工作
什么是多模态?
Multimodal data is essentially data belonging to multiple modalities.
多模态数据本质上是属于多种模态的数据。 模态的正式定义来自人机交互 (HCI) 系统的背景,其中模态被称为计算机和人类之间的单个独立输入和输出通道的分类(更多详细信息请参阅维基百科)。 常见的计算机-人类模式包括以下内容:
文本:Input and output through written language(e.g., chat interfaces).
语音:Voice-based interaction(e.g., voice assistants).
视频:Image and video processing for visual recognition (e.g., face detection).
手势:Hand and body movement tracking(e.g., gesture controls).
触控:Haptic feedback and touchscreens.
音频:Sound-based signals (e.g., music recognition, alerts).
生物识别:Interaction through physiological data (e.g., eye-tracking, fingerprints).
本综述重点关注处理文本、图像和表格。 理解此类数据所需的关键组件之一是多模态大语言模型 (LLM)。
多模态的本质是混合了多种多种模式和格式的数据:

什么是多模态大语言模型?
多模态大语言模型 (LLM) 本质上是基于 Transformer 的 LLM,已针对多模态数据进行预训练和微调,以分析和理解各种数据格式,包括文本、图像、表格、音频和视频。

理想情况下,真正的多模态模型不仅应该能够理解混合数据格式,还应该生成相同的数据格式。
文生图、图生文、文生音、文生视频
多模态编码阶段:
利用现有的成熟模型对各种模式的输入进行编码。
LLM理解和响应阶段
LLM被用作NExT GPT的核心代理。从技术上讲,他们采用Vicuna LLM,该LLM将来自不同模态的表示作为输入,并对输入进行语义理解和推理。它输出1)直接的文本响应和2)每种模态的信号标记,这些标记用作指示解码层是否生成多模态内容以及如果是则生成什么内容的指令。
多模态生成阶段
从LLM(如果有的话)接收具有特定指令的多模态信号,基于Transformer的输出投影层将信号令牌表示映射到后续多模态解码器可以理解的表示中。从技术上讲,他们采用了不同模态代的现成潜在条件扩散模型,即用于图像合成的稳定扩散(SD)、用于视频合成的Zeroscope和用于音频合成的AudioLDM。
目前,大多数可供实际使用的多模态LLM都是片面的,这意味着它们可以理解混合数据格式,但只能生成文本响应。
GPT-4V & GPT-4o (OpenAI):
Gemini (Google):
Claude (Anthropic):
想要构建完全开源的解决方案或担心数据隐私或延迟并更喜欢在内部本地托管所有内容,可以借助目前最流行的开放和开源多式联运模型构建:
LLaVA-NeXT: An open-source multimodal model with capabilities to work with text, images and also video, which an improvement on top of the popular LLaVa model
PaliGemma: A vision-language model from Google that integrates both image and text processing, designed for tasks like optical character recognition (OCR), object detection, and visual question answering (VQA).
Pixtral 12B: An advanced multimodal model from Mistral AI with 12 billion parameters that can process both images and text. Built on Mistral’s Nemo architecture, Pixtral 12B excels in tasks like image captioning and object recognition.
目前为止最为强大的多模态模型是Open-AI的GPT-4.o
多模态RAG系统的工作流
多模态RAG系统的构建流程与本篇博客的构建选择:

不好理解的一部分?
端到端的工作流:
如何去理解Summary?为什么图像、表格、和文本中在嵌入的时候都变成了Image Summary、Table Summary、Text Summary?
Option 1:
选择1缺陷的原因是多模态嵌入模型通常无法对这些视觉图像中的数字等粒度信息进行编码,并将其压缩为有意义的嵌入。
Option 2:
选项 2 受到严重限制,因为我们最终不会在该系统中使用图像,即使它可能包含有价值的信息,并且它不是真正的多模式 RAG 系统。
Option 3:
将继续使用选项 3 作为我们的多模态RAG 系统工作流程。 在此工作流程中,我们将从图像、表格以及可选的文本块中创建摘要,并使用多向量检索器,这可以帮助根据相应的原始图像、表格和文本元素映射和检索原始图像、表格和文本元素。
Multi-Vector Retrieval Workflow
考虑到我们将在上一节中讨论的工作流程,对于我们的检索工作流程,我们将使用如下图所示的多向量检索器,正如 LangChain 博客中推荐和提到的那样。 多向量检索器的主要目的是充当包装器,并帮助将每个文本块、表格和图像摘要映射到实际的文本块、表格和图像元素,然后可以在检索期间获得这些内容。

首先使用 Unstructed 等文档解析工具分别提取文本、表格和图像元素。 然后,我们将把每个提取的元素传递到 LLM 中,并生成详细的文本摘要,如上所示。 接下来,我们将使用任何流行的嵌入器模型(例如 OpenAI Embedders)将摘要及其嵌入存储到向量数据库中。 我们还将每个摘要的相应原始文档元素(文本、表格、图像)存储在文档存储中,文档存储可以是任何数据库平台,例如 Redis。
当用户提出问题时,首先,多向量检索器检索相关摘要,这些摘要在语义(嵌入)相似性方面与问题相似,然后使用公共的 doc_ids、原始文本、表格和图像 返回的元素将进一步传递给 RAG 系统的 LLM 作为回答用户问题的上下文。
多模态RAG的架构细节
- Load all documents and use a document loader like unstructured.io to extract text chunks, image, and tables.
- If necessary, convert HTML tables to markdown; they are often very effective with LLMs
- Pass each text chunk, image, and table into a multimodal LLM like GPT-4o and get a detailed summary.
- Store summaries in a vector DB and the raw document pieces in a document DB like Redis
- Connect the two databases with a common document_id using a multi-vector retriever to identify which summary maps to which raw document piece.
- Connect this multi-vector retrieval system with a multimodal LLM like GPT-4o.
- Query the system, and based on similar summaries to the query, get the raw document pieces, including tables and images, as the context.
- Using the above context, generate a response using the multimodal LLM for the question.
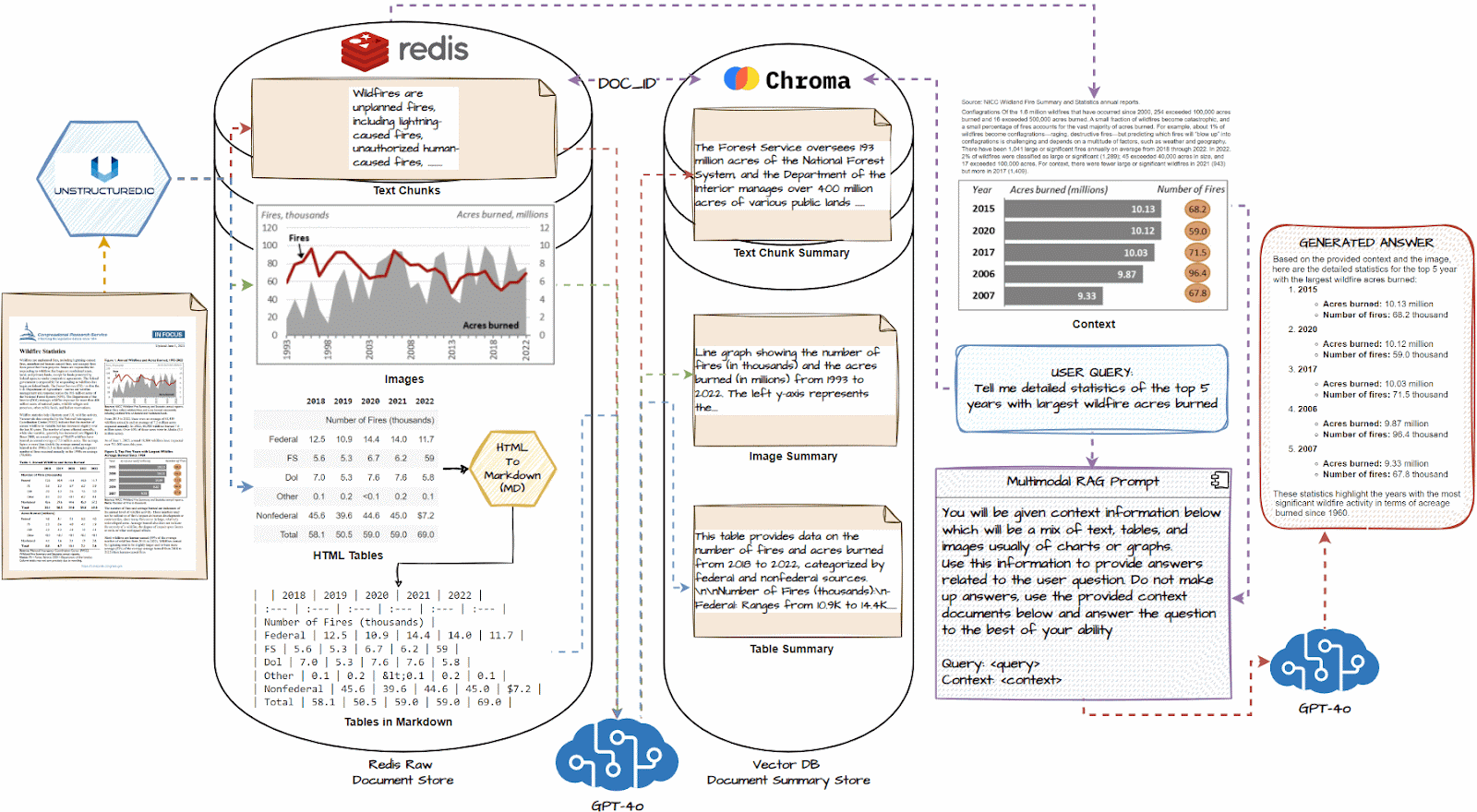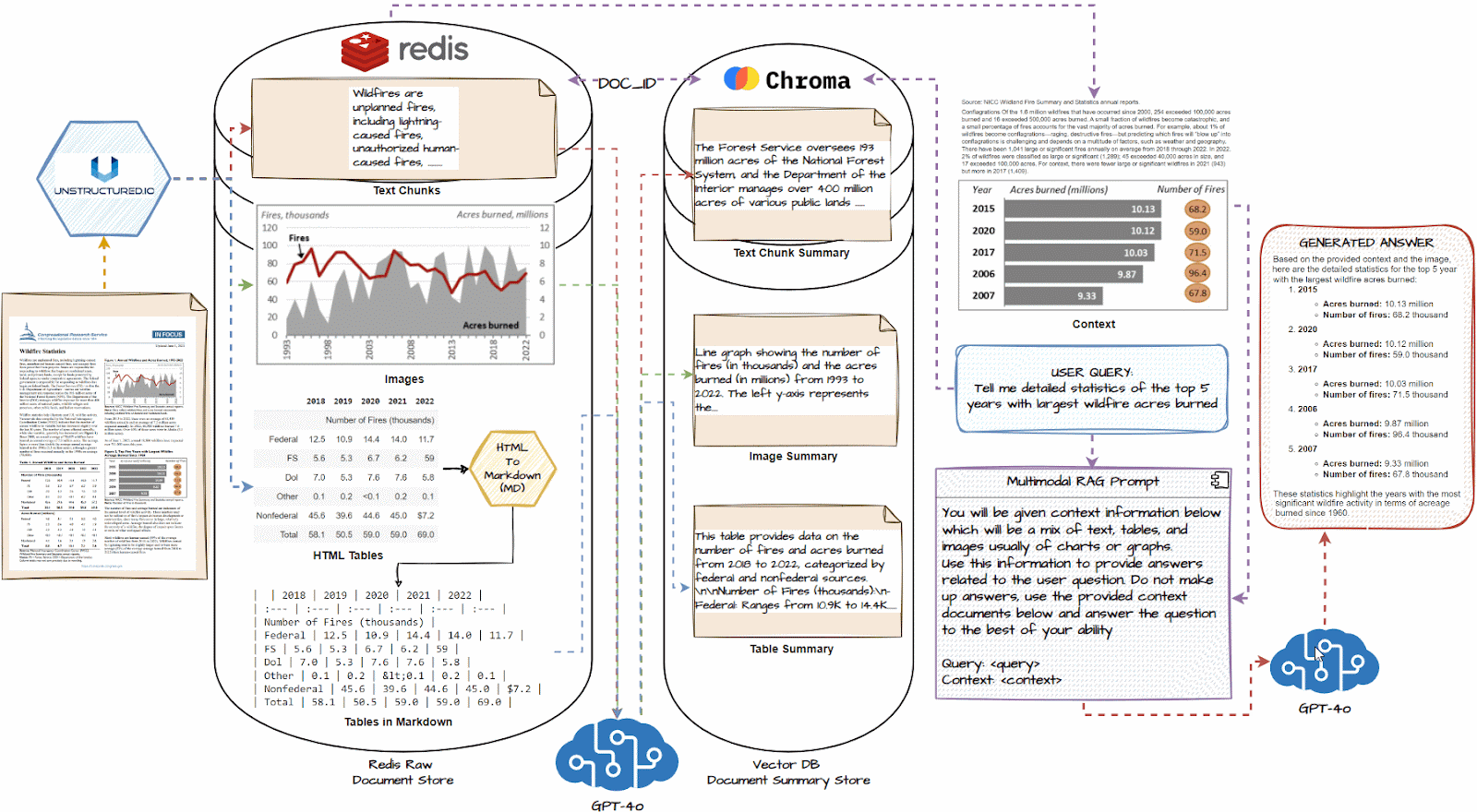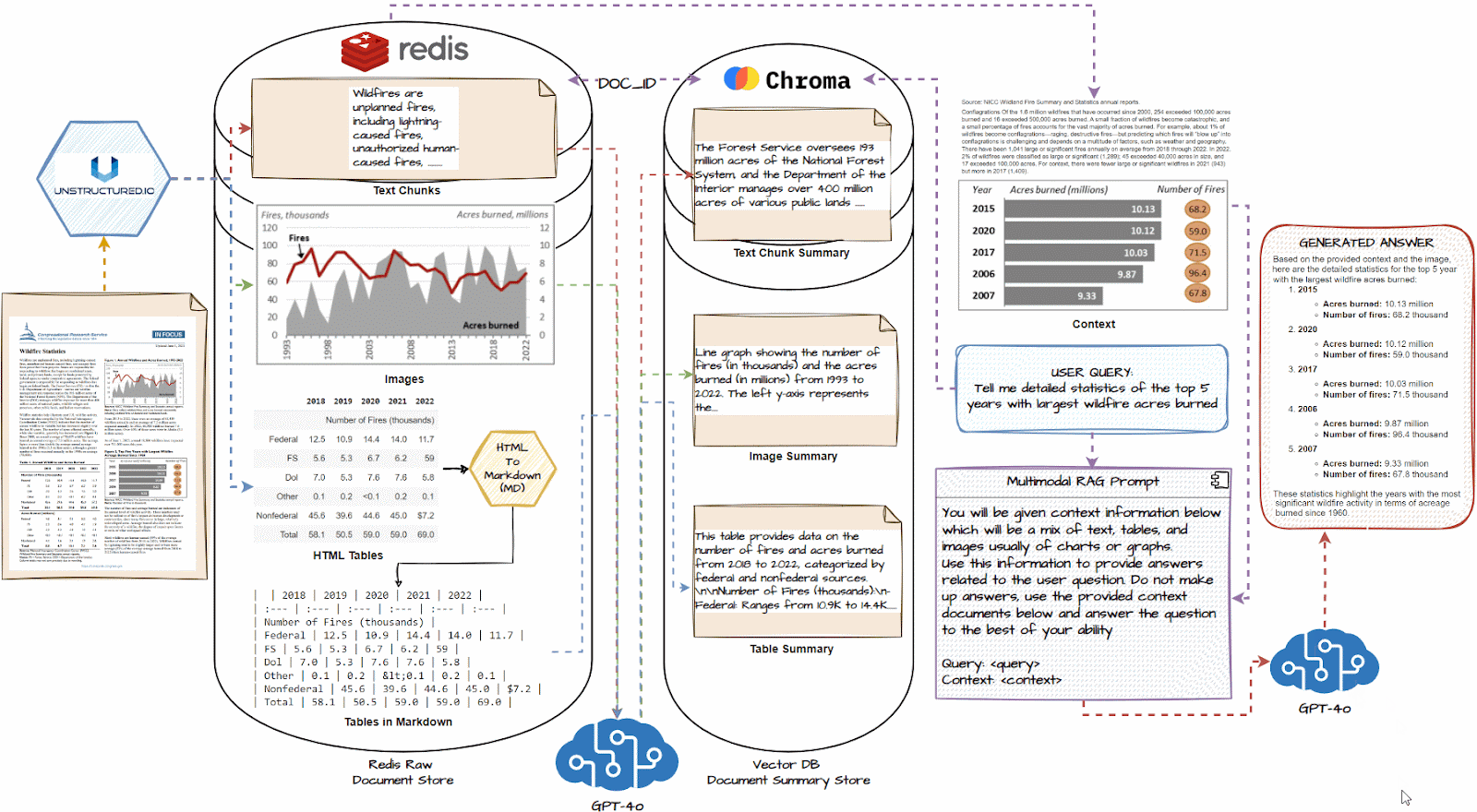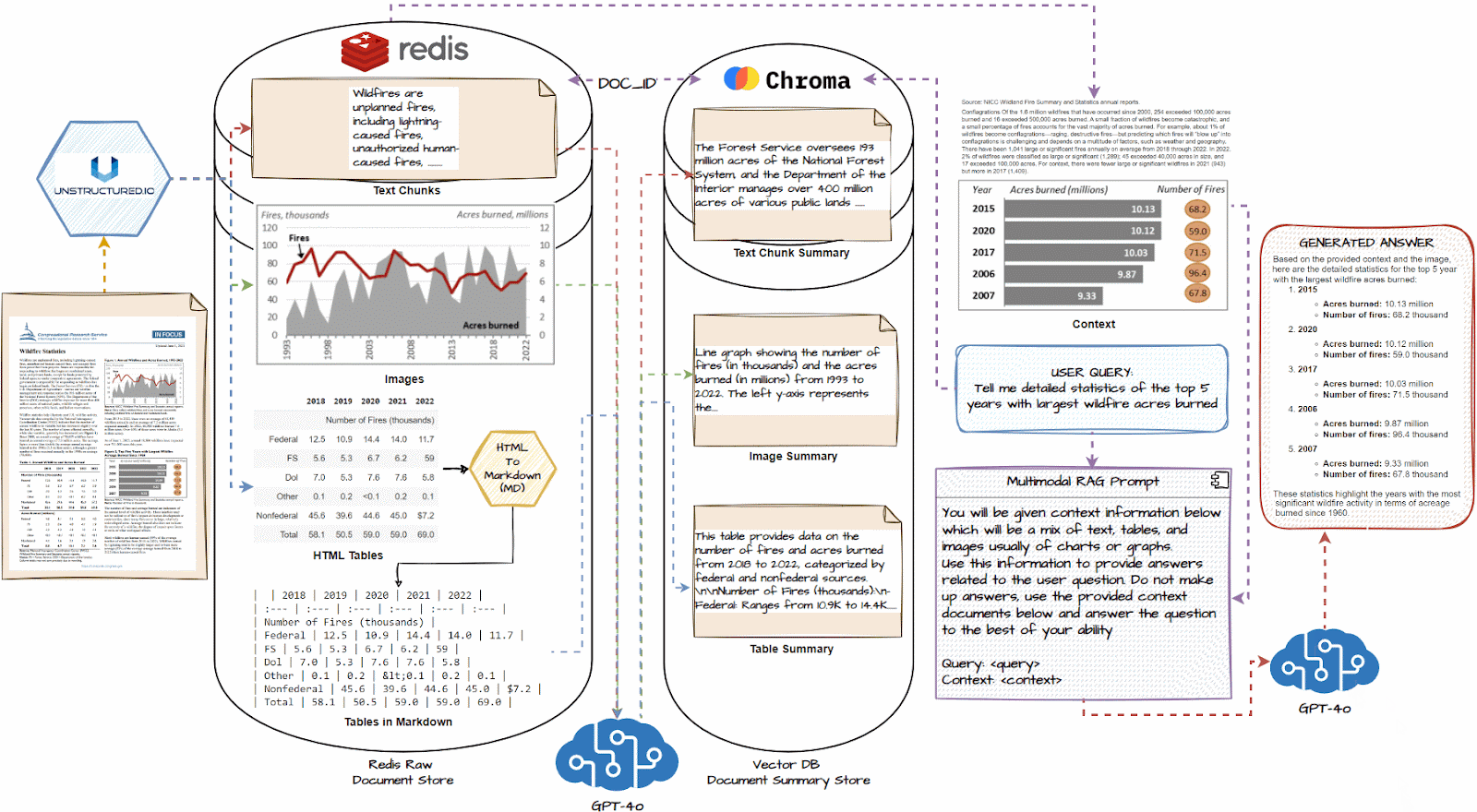
1.加载所有文档,并使用类似unstructure.io的文档加载器提取文本块、图像和表格。
2.如有必要,将HTML表格转换为markdown;他们通常对LLM非常有效
3.将每个文本块、图像和表格传递到GPT-4o等多模式LLM中,并获得详细的摘要。
4.将摘要存储在向量数据库中,将原始文档片段存储在Redis等文档数据库中
5.使用多向量检索器使用公共document_id连接两个数据库,以识别哪个摘要映射到哪个原始文档块。
6.将这个多向量检索系统与GPT-4o等多模态LLM连接起来。
7.查询系统,并根据与查询类似的摘要,获取原始文档片段,包括表格和图像,作为上下文。
8.使用上述上下文,使用多模态LLM生成问题的答案。